

今回はpandasチュートリアルの五回目になっています。
前回のがまだという方は↓の記事を参照ください。
【python】データ分析のためのpandasの使い方④:統計量の求め方
全てサンプルコードを記載してあります。各々のpythonの環境で実際に手を動かしながら読み進めていってください。
サクッとやりたい方は、google colaboratoryが簡単でおすすめです。
pythonのグループ化とは?
簡単に説明するとこの様になっています。
- 特定の列を基準にデータをグループ化
- グループ化されたデータに対して集計処理を行うことができる
- SQLのGROUP BY句に相当する機能
例として、購買データのトランザクションを男性・女性でグループ化し、それぞれの平均値や分散を出して、それぞれのグループの特長を掴んだりします。
グループ化は、データ分析において非常に頻繁に用いられる機能であり、pandasライブラリーの中でも重要な機能です。
データの準備
ではまずデータセットの準備をしましょう。
前回使った、’tips’というあるレストランの売上とチップをまとめたデータを使いましょう。
|
1 2 3 4 5 |
import pandas as pd import seaborn as sns df = sns.load_dataset('tips') df |
これで’tips’のデータフレームができました。
groupby()の使い方
Pythonには、データフレームの行や列をグループ化するためのgroupby() 関数があります。groupby() 関数は、一つまたは複数の列を指定してデータフレームをグループ化し、特定の列の値に基づいてデータを分類することができます。
単一の列でのグルーピング
データフレームの特定の列に基づいてグループ化するには、groupby() 関数を使用し、引数にグループ化したい列を指定します。
その後、グループごとの統計量を計算したり、グループごとに処理を実行したりすることができます。
例として、size(人数)列に基づいてデータをグループ化してみましょう。以下のようにコードを書くことができます。
|
1 2 3 4 5 6 7 8 |
# size列に基づいてグループ化する df_size = df.groupby("size") # グループごとの平均値を計算する mean_by_size = df_size.mean() # 結果を表示する mean_by_size |
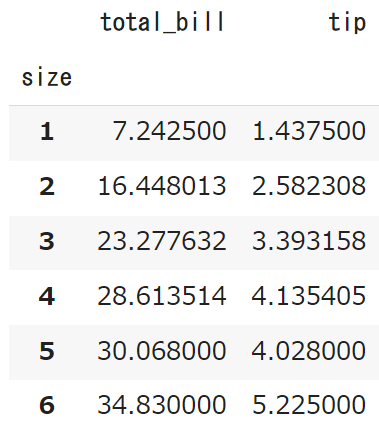
1~6人の場合のtotal_bilとtipsの平均値が出てきましたね。
当たり前ですが、人数が増えるほど平均値も上がっていきますね。
ただ、2人から6人と3倍になってもtotal_billが3倍になるわけではないです。
ちなみに上記の書き方だと、グループ化してから別の行で平均値を求めていましたが、1行にまとめる事も出来ます。
また対象のカラムに絞って平均値を求める事も出来るので、一緒にやってみましょう。
sizeでグループ化したあと、tipだけの平均値を求める
|
1 2 |
# tipの平均値を求める df.groupby("size")['tip'].mean() |
->
size
1 1.437500
2 2.582308
3 3.393158
4 4.135405
5 4.028000
6 5.225000
複数列でのグルーピング
複数列でのグルーピングを行うには、groupby()メソッドの引数に複数の列名をリスト形式で指定します。
以下は、seabornのtipsデータセットを使って、dayとsexの2つの列でグルーピングを行い、total_billの平均値を求める例です。
|
1 2 3 |
df_grouped = df.groupby(['day', 'sex'])['total_bill'].mean() df_grouped |
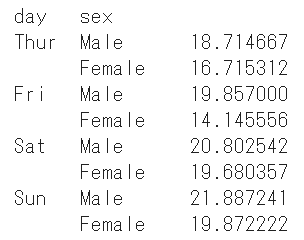
これで、曜日毎の男性(Male)、女性(Female)の平均値を求める事ができました。
groupby()の高度な使い方
グループ化されたデータフレームを操作する際には、groupbyオブジェクトのaggメソッドやapplyメソッドを使用することができます。これらのメソッドを使用することで、各グループごとに複数の統計量を計算することができます。
また、groupbyオブジェクトのsizeメソッドを使用することで、各グループの要素数をカウントすることができます。
さらに、groupbyオブジェクトのget_groupメソッドを使用することで、特定のグループを取り出すことができます。
下記の使い方を見ていきましょう。
- agg()
- size()
- get_group()
- apply()
複数の統計量を同時に計算する
複数の統計量を同時に計算する方法には、groupby()メソッドにagg()メソッドを組み合わせて使う方法があります。
agg()メソッドを使うことで、指定した列に対して複数の統計量を同時に計算することができます。
sexでグループ化した後に、total_billの合計とtipの平均を一緒に求めてみます。
|
1 |
df.groupby('sex').agg({'total_bill': 'sum', 'tip': 'mean'}) |
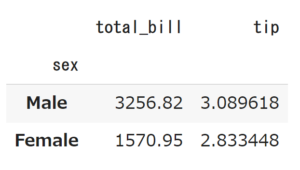
またひとつのカラムに対して、平均値、最大値、最小値を一緒に求めたい場合はリストで渡してあげます。
|
1 2 |
# 平均、最大値、最小値を求める df.agg({'tip': ['mean', 'max', 'min']}) |
->
tip
mean 2.998279
max 10.000000
min 1.000000
各グループの要素数をカウント
size()メソッドを使用して各グループの要素数をカウントすることができます。
LunchかDinnerの値が入っているtimeカラムでグループ化し、それぞれの個数を求めてみましょう。
|
1 2 3 4 |
# timeカラムでグループ化 df_time = df.groupby('time') # それぞれの個数を求める df_time.size() |
->
time
Lunch 68
Dinner 176
Dinnerの方が圧倒的に多い事が分かりましたね。
グループ化されたデータフレームから指定したグループの行を取得する
groupbyメソッドによって返されたオブジェクトに対して、get_groupメソッドを使う事で、グループ化されたデータフレームから指定したグループの行を取得できます。
これはちょっと難しく感じるかもしれませんが、理解すればなんて事ないです。
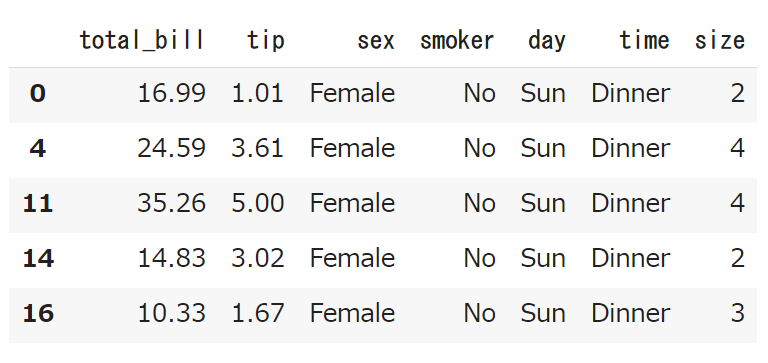
性別でグループ化したあとに、Femaleの先頭5行だけ取得してみましょう。
|
1 2 |
# sex列でグルーピングした後のFemaleの先頭5行だけ取得 df.groupby('sex').get_group('Female').head() |
データフレームに関数を適用してみよう
最後にグループ化と近い処理として、apply()を使ってDataFrameやSeriesに関数を適用してみましょう。
パッと聞くと難しく見えますが、実務でも非常に使う機会が多いので、しっかりと覚えていきましょう。
apply()は、pandas DataFrameやSeriesに対して、関数を適用するためのメソッドです。DataFrameやSeriesの各要素に対して、関数を適用して新しいSeriesやDataFrameを作成することができます。
要は、カラムを指定してそこだけ関数を適用させるイメージです。
では実際に、total_billとtipsを足し算する関数を作成し、それをapply関数で適用させ、新しくtotalカラムを作ってみましょう。(total_billとtipsが足されたカラムです。)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 新しくデータフレームを作成 df_total = sns.load_dataset('tips') # total_bill列とtip列を合計して、新しい列totalを作成する関数 def sum_total(row): return row['total_bill'] + row['tip'] # apply()でsum_total関数を適用して、新しい列totalを作成する df_total['total'] = df_total.apply(sum_total, axis=1) # 結果を表示する df_total.head() |
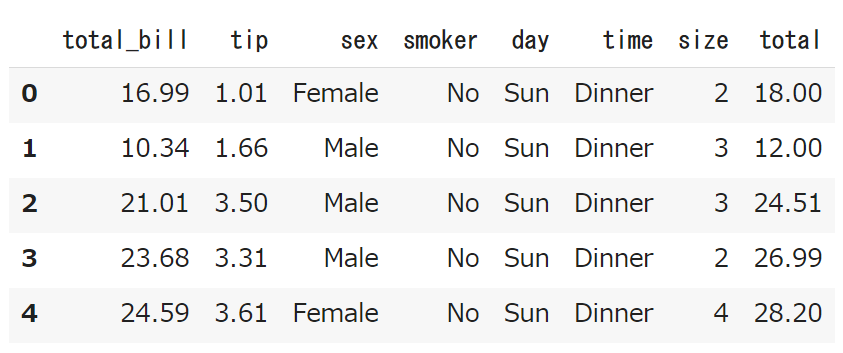
一番右にtotalが出来ましたね!
lambdaを使ってシンプルに
ただ、上記のapplyのやり方だとdefで関数を作っているのでどうしてもコードが煩雑になりがちです。
特にコードは誰かに読まれるという前提のもと作成する事が大切ですので、もっと分かりやすくしたくなりますね。
そんな時に役にたつのがlambdaです。
- lambdaはPythonの無名関数を作成する方法であり、1行の関数を定義できます。
- lambdaは一時的な関数を作成するために使用され、defキーワードで定義される関数とは異なり、名前を持たず、1つの式で表されます。
- lambda式は、式の評価結果がそのまま戻り値となります。
- lambda式の一般的な構文は、
lambda 引数: 式となっています。
では上でやったtotal_billとtipsを足し算する関数をlambdaを使ってかくと下記の様になります。
|
1 2 3 4 5 6 7 8 |
# 新しくデータフレームを作成 df_total = sns.load_dataset('tips') # applyメソッドでtotal_billとtipを足してtotalカラムを作成 df_total['total'] = df_total.apply(lambda x: x['total_bill'] + x['tip'], axis=1) # 結果を表示する df_total.head() |
非常にシンプルになって、可読性が上がりましたね。
ちなみに、apply()のaxisに1を指定する事で行方向に操作する事ができます。
まとめ
今回もなかなかのボリュームだったと思います。
- 単一のカラムでのグルーピング
- 複数カラムでのグルーピング
- グループ化してからの統計量算出
- groupby()の高度な使い方
データサイエンスをする上でグループ化は絶対に必要になってきますので、自分の思い通りに抽出出来るようにひとつずつマスターしていきましょう!











