

今回はpandasチュートリアルの六回目になっています。
前回のがまだという方は↓の記事を参照ください。
【python】データ分析のためのpandasの使い方⑤:グループ化しよう!
全てサンプルコードを記載してあります。各々のpythonの環境で実際に手を動かしながら読み進めていってください。
サクッとやりたい方は、google colaboratoryが簡単でおすすめです。
NaNとは何か?
簡単い言うとNaN(ナン)は、欠損値を表します。NaNは、「Not a Number」の略称で、数値の意味を持たない値です。
例えば、0で割り算をした場合や、0の累乗を計算した場合など、数学的に意味のない計算結果を表します。
また、NumPyやpandasといったPythonのデータ解析ライブラリでは、NaNは欠損値を表す特別な値として扱われます。NaNを含むデータに対して、様々な処理を行うことができます。
NaNとNoneの違いは?
欠損値と聞くとNoneを思い浮かべる人も多いでしょう。コチラの方が有名ですしね。
しかし、NaNとNoneは別の物になります。
Noneとは何?
Noneは、Pythonにおけるオブジェクトの「無」を表す特別な値です。
Noneは、オブジェクトが存在しないことを示すために使われます。たとえば、関数が何も返さない場合には、Noneが返されます。
また、リストや辞書などの要素にNoneを割り当てることができます。
具体的な違い
では実際の所何が違うのか?を見ていきましょう。
- NaNは数値計算の結果として生じることがあり、float型で表現されます。
- NoneはPythonオブジェクトの値として、オブジェクトが存在しないことを示すために使われます。
- NaNは、NumPyやpandasなどのライブラリで使用されることが多く、数値の欠損値を表します。
- 一方、Noneは、Pythonの組み込み型として使用され、オブジェクトが存在しないことを表します。
- NaNは、比較演算子を使用して比較することができません。これは、NaNがどのような値かを定義するための明確なルールが存在しないためです。
- Noneは、比較演算子を使用して比較することができます。
細かい点ですが、この様な違いがあります。
NaNの原因と発生方法
NaNが発生する原因としては、以下のようなものがあります。
- 計算上の不正確さや未定義の値が含まれる場合
- 欠損値が含まれる場合
NaNは、計算上の問題がある場合に発生することが多いです。たとえば、0で割るとNaNになります。また、$\sqrt{-1}$を計算するとNaNになります。
また元のデータに欠損値が含まれる場合には、pandasやNumPyなどのライブラリでNaNとして扱われます。
では実際にNaNを出してみましょう。
|
1 2 3 4 5 |
import numpy as np # 数値の計算によってNaNが発生する例 a = np.sqrt(-1) print(a) # nan |
->NaN
|
1 2 3 4 5 |
# 欠損値を含むデータによってNaNが発生する例 import pandas as pd df = pd.DataFrame({'A': [1, 2, np.nan], 'B': [4, np.nan, 6], 'C': [7, 8, 9]}) print(df) |

NaNの扱い方
では実際にNaNがあった場合の対処法を見ていきましょう。
NaNがあるとデータ分析や機械学習モデルの構築が困難になることがあります。そのため、NaNの扱い方を知っておくことは重要です。
以下は、NaNの扱い方についてのいくつかの方法です。
- 欠損値を含む行/列の削除
- 欠損値の補完方法
- 欠損値の代替方法
詳しくみていきましょう。
欠損値を含む行/列の削除
欠損値を含む行を削除するには、pandasのdropna()メソッドを使用します。このメソッドは、欠損値を含む行を削除することができます。
まずはサンプルデータを作成してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd import numpy as np data = { 'name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'], 'age': [25, np.nan, 30, np.nan, 35], 'height': [165, 180, np.nan, 175, np.nan], 'weight': [55, 70, 60, np.nan, np.nan] } df = pd.DataFrame(data) df |
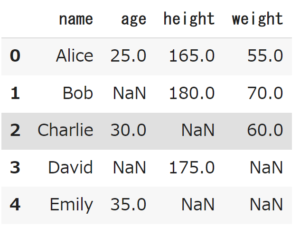
無事にNaNのあるデータフレームができました。
isna()を使ってNaNを判定
isna()は、pandasのメソッドの1つで、各要素が欠損値(NaNまたはNaT)かどうかを判定するために使用されます。
具体的には、データフレームまたはシリーズの各要素に対して、欠損値の場合はTrue、それ以外の場合はFalseを返します。欠損値を検出する際によく使用されます。
|
1 2 |
# NaNの判定 df.isna() |
->
name age height weight
0 False False False False
1 False True False False
2 False False True False
3 False True False True
4 False False True True
NaNの箇所がTrueで表示され、NaNがある事が分かりましたね。
行の削除
では実際にNaNの行を削除してみましょう。
|
1 2 |
# 欠損値を含む行の削除 df.dropna(axis=0) |
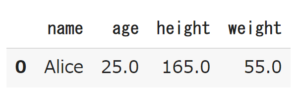
列の削除
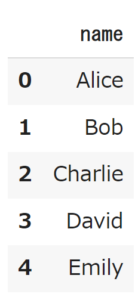
では続いて列の削除を見ていきましょう。
axis=1にすると列方向に削除されます。
|
1 2 |
# 欠損値を含む列の削除 df.dropna(axis=1) |
データフレームの上書き
上記のやり方で簡単に削除する事ができました。
しかし、注意点としてこのままではもとのデータフレームからは削除されません。
また’df’で中身を見るとNaNが入っています。
↑もとに戻っています。
そんな場合は、inplace=Trueとすることで、元のデータフレームを更新することができます。
|
1 2 |
# もとのデータフレームを更新 df.dropna(axis=0, inplace=True) |
また下記のやり方でも大丈夫です。
|
1 2 |
# もとのデータフレームを更新 df = df.dropna(axis=0) |
いろいろな欠損値の補完方法
続いて、欠損値を削除せずに別の値で補完する方法を見ていきましょう。
代表的な物として以下の3つがあります。
- 平均値で補完する方法
- 中央値で補完する方法
- 最頻値で補完する方法
この他にも機械学習による補完もありますが、上級になってしまうので割愛します。
平均値で補完
欠損値を平均値で補完する方法は、欠損値のある列の平均値を計算し、欠損値にその平均値を代入する方法です。
mean()を使う事で、一括で全カラム補完してくれます。
|
1 2 |
# 平均値で補完 df.fillna(df.mean()) |
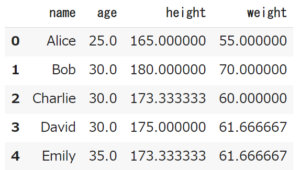
対応する列の平均値で補完する事ができました。
中央値で補完する方法
欠損値を中央値で補完する方法は、欠損値のある列の中央値を計算し、欠損値にその中央値を代入する方法です。
|
1 2 |
# 平均値で置換 df.fillna(df.median()) |
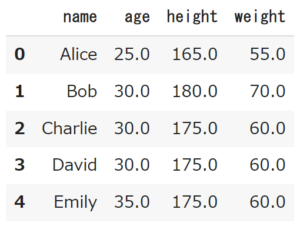
最頻値で補完
欠損値を最頻値で補完する方法は、欠損値のある列の最頻値を計算し、欠損値にその最頻値を代入する方法です。
最頻値に関しては、mode()を使うのですが、df.fillna(df.mode())とする事ができず、1カラムずつ補完していく必要があります。
|
1 2 3 4 5 |
df['age'] = df['age'].fillna(df['age'].mode()[0]) df['height'] = df['height'].fillna(df['height'].mode()[0]) df['weight'] = df['weight'].fillna(df['weight'].mode()[0]) df |
この様にする事で最頻値にする事ができます。
NaNの処理の注意点
ここまでに、NaNの処理方法として以下の事を学びました。
- 削除
- 列方向に削除
- 行方向に削除
- 補完
- 平均値
- 中央値
- 最頻値
しかし、NaNに対して意図もなく、とりあえず削除や補完をしてしまうと失敗します。
大事な事として、データに合わせて適切な処理を行う必要があるということです。
欠損値の数や分布、欠損値を含むデータの性質に応じて、補完や削除などの対処方法を選択する必要があります。
NaNを処理する時はこの点を気をつけて
とくに下記の点に注意しましょう。
- 行または列を除外するとデータの偏りが生じることがある
- 欠損値を除外するとデータが少なくなり、解析の信頼性が低下する可能性がある
- 欠損値の代替方法として平均値や最頻値などを使う場合、代替方法がデータの分布に影響を与えることがあるため、代替方法を決定する前にデータの分布を確認する必要がある
- 欠損値を代替する方法によっては、偽の相関関係が発生する可能性があるため、欠損値がどのように処理されたかについて常に明確な説明を記述する必要がある
まとめ
いかがでしたでしょうか?
実際のデータでは欠損値がある事がほとんどです。
「絶対に必要ないから削除しよう」と結論付けられれば簡単なのですが、判断に迷うことの方が圧倒的に多いでしょう。
ひとつひとつのデータの特性を掴み、正しい処理をする事が大切です。











