

今回はpandasチュートリアルの七回目になっています。
前回のがまだという方は↓の記事を参照ください。
【python】データ分析のためのpandasの使い方⑥:NaNについて!
今回はpandasのデータフレームに対して良く使う関数を見ていきましょう!
今までに学んできたのもにプラスして、データ分析で良く使う関数を紹介します。
全てサンプルコードを記載してあります。各々のpythonの環境で実際に手を動かしながら読み進めていってください。
サクッとやりたい方は、google colaboratoryが簡単でおすすめです。
info()でデータフレームの情報を見よう
まず一つ目がinfo()です。
.info()関数は、データフレームの情報を表示するために使われます。
具体的には、データフレームの各列のデータ型、欠損値の有無、メモリ使用量などを確認することができます。
この関数は、データフレームが大きい場合でも、非常に高速に情報を表示することができるため、データフレームの概要を素早く把握するために役立ちます。
データ準備
使い方を見て行く前に、まずはデータの準備をしましょう。
前にも使った、’tips’というあるレストランの売上とチップをまとめたデータを使いましょう。
|
1 2 3 4 5 |
import pandas as pd import seaborn as sns df = sns.load_dataset('tips') df |
これで’tips’のデータフレームができました。
info()の使い方
では実際に使い方を見ていきましょう。
非常にシンプルです。
|
1 2 |
# info()の使い方 df.info() |
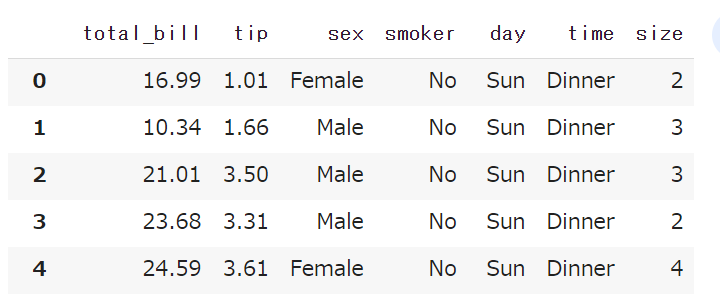
結果が↓コチラです。
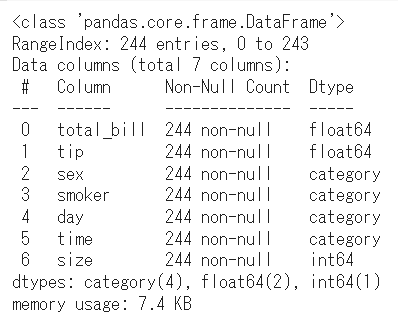
この例では、以下の情報を確認することができます。
RangeIndex:行数の範囲を表示しています。Column:データフレームのカラム名称Non-Null count:各カラムの欠損していないレコードの数dtypes:各カラムのデータ型を表示しています。memory usage:データフレームが占有するメモリ使用量を表示しています。
これ一発で各カラムの欠損値の数やデータ型を把握できるので便利ですね!
unique()でユニークな値を取得
unique()関数は、配列やシリーズオブジェクトのユニークな値を返す関数です。つまり、重複する要素を取り除いたユニークな値の配列を返します。
unique()の使い方
unique()はdf.unique()の様にデータフレームに対しては使えず、seriesに対して使う事ができます。
簡単に言うと、表全体に一括で使う事はできず、1列ずつ使うイメージです。
具体的に見ていきましょう。tipsのsizeカラムのユニークな値を見てみましょう。
|
1 |
df['size'].unique() |
-> array([2, 3, 4, 1, 6, 5])
この様に、1~6のユニークな値の配列が返されます。
unique()関数は、重複する要素を取り除いたユニークな値の配列を返します。
この関数を使用することで、データ内にどのような値が存在するのか、またそれらがいくつあるのかを簡単に確認することができます。
value_counts()でカウント
value_counts()は、pandasライブラリに含まれるSeriesオブジェクトのメソッドで、各要素の出現回数を数えることができます。
具体的には、Seriesに含まれるユニークな値ごとの出現回数を取得することができます。
頻度の高い値や異常値の検出、データの分布を理解する際に有用な関数です。
value_counts()の使い方
では使い方を見ていきましょう。
こちらもシリーズにしか使えませんので、sizeの各人数毎のカウントを見てみましょう。
|
1 |
df['size'].value_counts() |
->
2 156
3 38
4 37
5 5
1 4
6 4
この様な結果になりました。2が一番多く、156となっています。
value_counts()の引数
value_counts()では様々な引数を指定する事が出来、自分の好きな条件で結果を取得する事ができます。
以下は、value_counts()関数の基本的な構文です。
|
1 2 3 4 5 |
df['size'].value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True) |
normalize:出現回数を割合に変換するかどうかを指定します(デフォルトはFalse)。sort:出現回数が多い順に並び替えるかどうかを指定します(デフォルトはTrue)。ascending:昇順(True)または降順(False)で並び替えるかどうかを指定します(デフォルトはFalse)。bins:ヒストグラムのビン数を指定します(デフォルトはNone)。dropna:欠損値を無視するかどうかを指定します(デフォルトはTrue)。
この様になっています。
では、normalize、ascendingパラメータをTrueに設定し、出現回数を割合に変換し、昇順に並べ替えてみましょう。
|
1 |
df["size"].value_counts(normalize=True, ascending=True) |
->
1 0.016393
6 0.016393
5 0.020492
4 0.151639
3 0.155738
2 0.639344
この様になります。sizeが2の割合は全体の63.9%だという事が分かりましたね!
replace()で値を変換
replace()関数は、データフレーム内の値を置換するために使用されます。
この関数を使用すると、データフレーム内の特定の値を、指定した値や条件に基づいた値に置換することができます。
replace()の使い方
sex列の値を置換してみましょう。
sex列は、'Male'または'Female'の2つの値を持ちます。
Male→M、Female→Mにそれぞれ置換してみましょう。
replace()関数を使用するためには、まず置換前の値を指定します。次に、置換後の値を指定します。
最後に、オプションでinplace=Trueを指定することで、データフレーム自体を直接変更することができます。
|
1 2 3 |
df['sex'].replace('Male', 'M', inplace=True) df['sex'].replace('Female', 'F', inplace=True) df['sex'].head() |
->
sex
0 F
1 M
2 M
3 M
4 F
このように、値がFとMだけになります。
replace()関数は、文字列だけでなく、数値や論理値などの他のデータ型でも使用できます。また、正規表現を使用して、複数の値を一度に置換することもできます。
sort_values()で並び替え
sort_values()関数は、データフレームの特定の列または複数の列を基準にして行の並べ替えを行うことができます。
この関数を使用することで、データを整理して視覚化しやすくなったり、特定の列の値を比較することができたりします。
sort_values()の使い方
sort_values()関数は、次のような構文で使用します。
|
1 2 3 4 5 |
dataframe.sort_values(by, axis=0, ascending=True, inplace=False, ignore_index=False) |
引数は以下の通りです。
- by:並び替えの基準となる列名(str型)または複数の列名のリスト
- axis:並び替えを行う軸。0は行(デフォルト)、1は列を指定します。
- ascending:昇順または降順に並べ替えるかどうかのフラグ。Trueは昇順(デフォルト)、Falseは降順を指定します。
- inplace:並び替えたデータフレームを元の変数に上書きするかどうかのフラグ。Trueで上書きします。
- ignore_index:インデックスを再設定するかどうかのフラグ。Trueで再設定します。
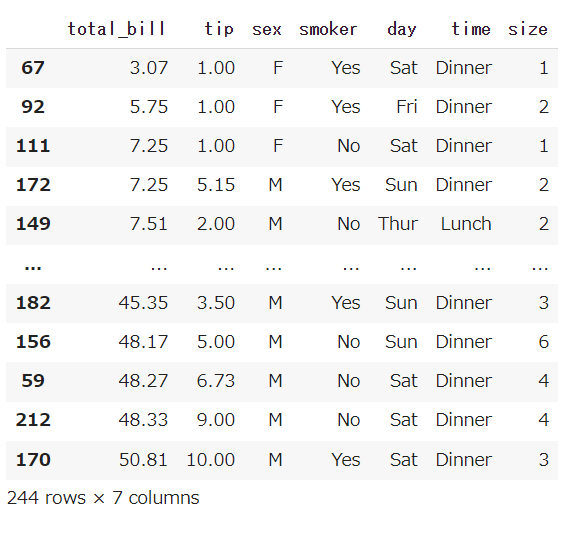
たとえば、total_billの昇順でソートする場合は以下の様に書きます。
|
1 2 |
# total_billの昇順でソート df.sort_values('total_bill') |
複数列を並び替える方法
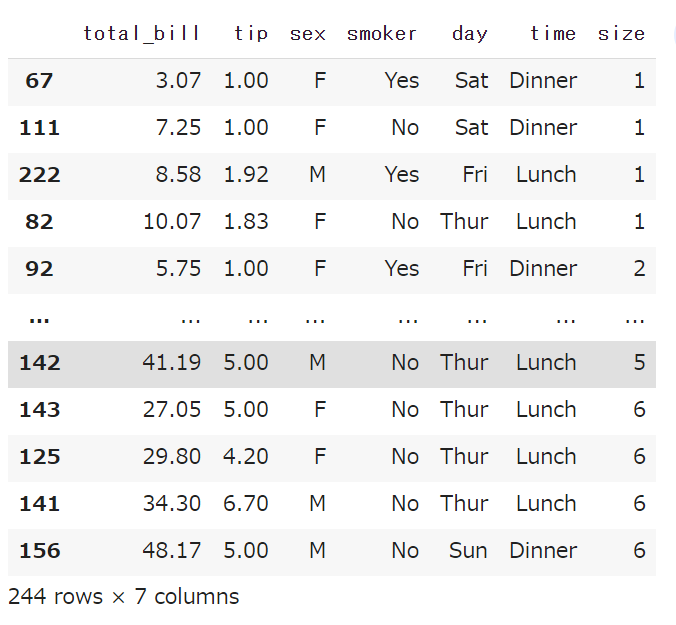
1カラムだけでなく、複数列を対象に並び替える事もできます。
ようは、tipsデータの中でsizeの値が同じ場合には、total_billの値でソートしたい場合、次のようにコードを書くことができます。
|
1 |
df.sort_values(['size', 'total_bill']) |
まとめ
いかがでしたでしょうか?
今回はデータ分析で良く使う関数の紹介をしました。
特に実務ではデータフレームに対して何かしらの処理をする事が非常に多いです。
そのためにも、今回学んだ事はしっかりと身に着けましょう!











