

今回の講座ではmatplotlibでヒストグラムと棒グラフを作成する方法を紹介します。
とくに
- ヒストグラムと棒グラフの違いってなに?
- matplotlibでどうやって描画するの?
このような疑問を持っている人にうってつけの内容になっています。
データ分析業務において、ヒストグラム・棒グラフを見ない現場はないと思いますので、しっかりと押さえておきましょう。
ヒストグラムと棒グラフってなに?
いきなりmatplotlibで描画する方法にいくのではなく、まずはヒストグラムと棒グラフがいったいどういうものかを理解しましょう。
そのためにはまず、
特長量には連続する値とカテゴリカルな値があることを理解しましょう。

まず特長量という単語の意味を知っている人も多いと思いますが、知らない人のためにシンプルに説明すると、テーブルデータのカラムだと思ってください。
例えば、前回の講座でも使った「tips」データですが、全てのカラムは.columnsで見る事ができます。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 各種インポート import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt # tipsデータをデータフレーム化 df = sns.load_dataset('tips') # カラム名を取得 df.columns |
![]()
total_billからsizeまで、合計7個のカラムがある事が分かりました。
続いて、連続する値とカテゴリカルな値についてですが、まずカテゴリカルな値について説明します。
カテゴリカルな値とは?
簡単に言うと、カラムに入るデータがカテゴリー分けされているものです。
例えば、性別であったり、血液型、ログデータの場合はOSの種類やデバイスの種類などがそれにあたります。
tipsデータでは以下のものが該当します。
- sex:性別
- smoker:煙草を吸うか吸わないか?
- day:何曜日か?
- time:ランチかディナーか?
連続する値とは?
連続する値は、カテゴリーのように区分けされておらず、無数の数値が入るカラムのことです。整数だけの場合や少数が入る場合もあります。
例えば、身長や体重、トランザクションデータでは店舗の売上や購買点数などです。
tipsデータでは以下のものが該当します。
- total_bill:お会計学
- tip:チップの金額
- size:来店人数
このような違いがあります。
ちなみにデータ方からも推測することができます。
df.info()で見れます。
|
1 |
df.info() |
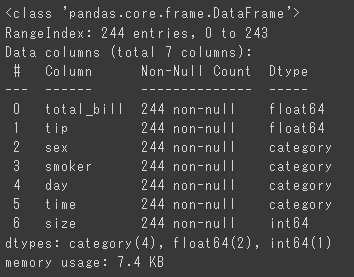
Dtypeと書かれていいる箇所がデータ型にあたります。
categoryと書かれているカラムがカテゴリカルな値で、float64やint64と書かれているカラムが連続する値です。
ちなみにfloatの場合は小数点以下も格納でき、intの場合は整数だけです。
このようにデータ型からも見てとる事ができますが、データによっては本当はカテゴリーなのにintだったりする場合もありますので注意しましょう。
ヒストグラムとは何か?
ヒストグラムは連続する値をplotする場合に使います。
ただ、値をそのままplotするのではなく、ある区間ごとに区切ります。
各区間の個数や数値のばらつきを表現するグラフです。
ちなみにこの区切った区間のことを「bins」と呼びます。
例えば、tipsデータの「total_bill」を10個に区切ったヒストグラムが↓です。
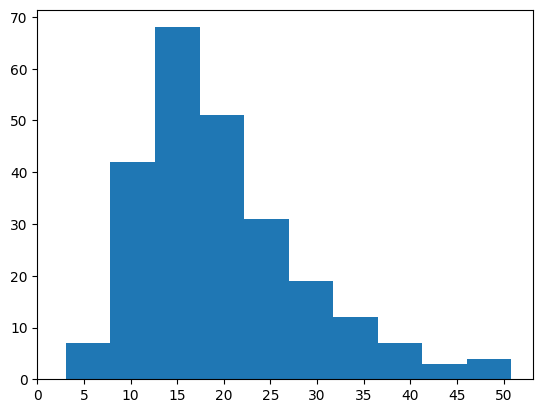
支払い額の散らばりを見る事ができますね!
x軸の単位はドルですので、15ドルから20ドル前後の支払いが多い事が分かりました。
棒グラフとは何か?
一方、棒グラフは、カテゴリデータの分布状況を表現するために用いられます。
ある学校の生徒の血液型の分布を見たり、ある企業の年度毎の売上をplotしたりします。
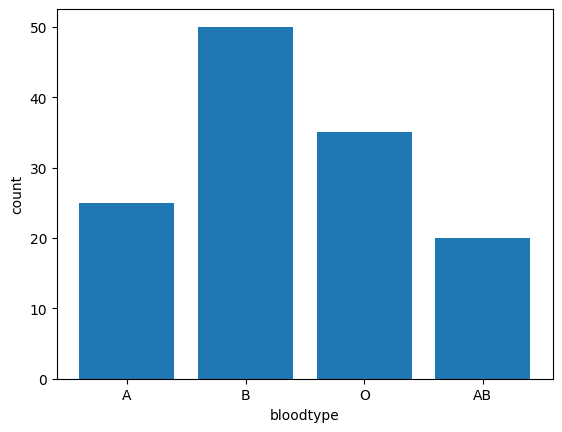
x軸が血液型でカテゴリーごとになっていますね。
y軸はそれぞれの血液型の人数を表しています。
今回のy軸の単位は人数ですが、割合で表す場合も多いです。
plt.hist()でヒストグラムをplotしよう
では実際にmatplotlibでヒストグラムを作成する方法を見ていきましょう。
| 引数 | 説明 | 詳細 |
| x | x軸を指定 |
|
| bins | 階級数を指定 |
|
| range | ビンの表示範囲を指定 |
|
| density | 累積密度関数 |
|
| weights | 重み |
|
| cumulative | 累積ヒストグラム |
|
| bottom | 下部の余白 |
|
| histtype | ヒストグラムの種類 |
|
| align | 棒の中心の位置 |
|
| orientation | 棒の向き |
|
| rwidth | 棒の太さ |
|
| log | 対数目盛 |
|
| color | 棒の色の変更 |
|
| label | 凡例 |
|
| stacked | 積み上げヒストグラム |
|
| data | dataframeを指定 |
|
これだけの引数をとる事ができますが、絶対に必要なのはXだけです。
あまり使わないものも多いので、主要なものだけ紹介します。
ヒストグラムのplot
では上でdataframe化したtipsデータを使ってplotしてみましょう。
total_billをxに指定します。
|
1 |
plt.hist('total_bill', data=df) |
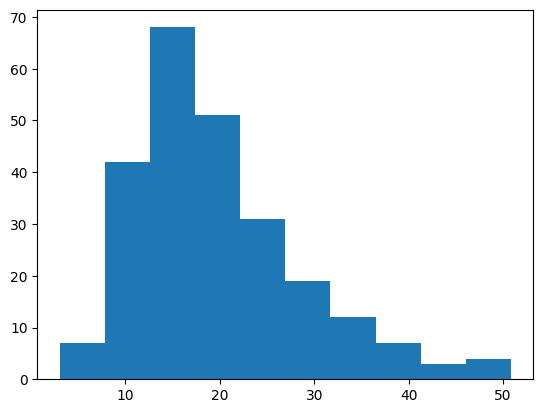
ビンが10個のヒストグラムが作れました。
では続いてビンの数を倍の20にしてみましょう。
|
1 |
plt.hist('total_bill', bins=20, data=df) |
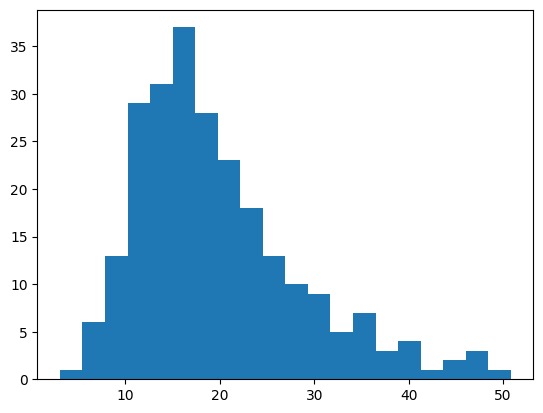
20にすることで、よりデータの分布の詳細が見れるようになりましたね。
あまり細かくし過ぎると、逆に見辛くなってしまうので、データセットに合わせた値を設定しましょう。
累積値をplot
|
1 |
plt.hist('total_bill', cumulative=True, data=df) |
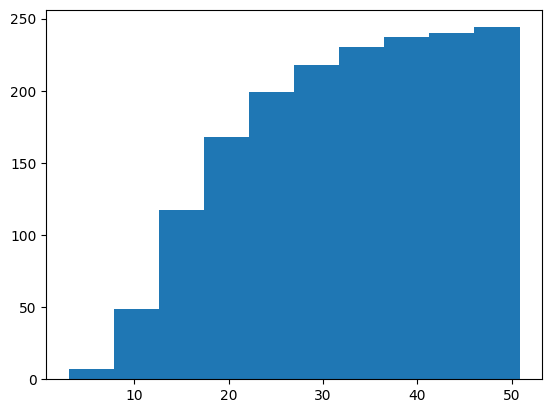
ときどき累積値でplotすることもあります。
cumulativeをTrueにするだけですので簡単です。
ヒストグラムの見え方を変える
ヒストグラム自体の色や形を変えることもできます。
棒の幅と色を変更してみましょう。
|
1 |
plt.hist('total_bill', rwidth=0.7, color='green', data=df) |
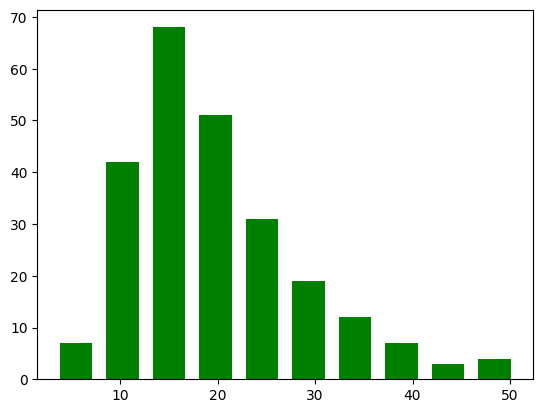
続いて、棒の向きを横向きにして凡例を追加してみましょう。
凡例は今までと同じ方法で追加できます。
|
1 2 |
plt.hist('total_bill', orientation='horizontal', label='total_bill', data=df) plt.legend() |
積み上げヒストグラム
あと積み上げヒストグラムも良く使います。
ランダムな値を作成してplotしてみましょう。
積み上げる場合は↓のようにリストでxを指定します。
また、それぞれのcolorもリストで渡すことで変更することができます。
|
1 2 3 4 5 6 7 8 |
import numpy as np # 平均100、標準偏差30のランダムな値を300個生成 x = np.random.normal(100, 30, 300) # 平均120、標準偏差20のランダムな値を50個生成 y = np.random.normal(120, 20, 50) plt.hist([x, y], histtype='barstacked', color=['blue', 'red']) |
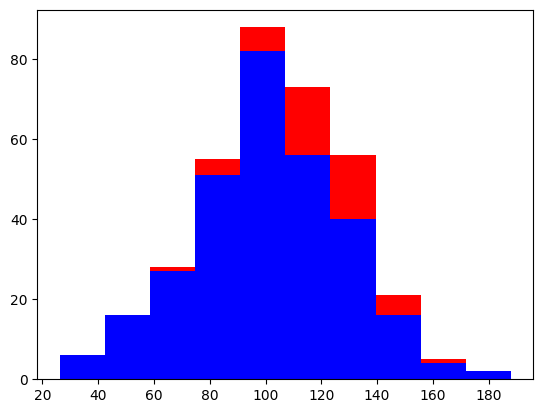
ちなみにhisttypeではなくstackedを使っても一緒の結果になります。
|
1 |
plt.hist([x, y], stacked=True, color=['blue', 'red']) |
plt.bar()で棒グラフをplotしよう
棒グラフをplotするさいはplt.bar()でplotすることができます。
plt.bar(x,height,width=0.8,bottom=None,
color=None, align=‘center’,data=None)
| 引数 | 説明 | 詳細 |
| x | x軸を指定 |
|
| height | 各棒の高さ |
|
| width | 棒の太さ |
|
| bottom | 下部の余白 |
|
| color | 棒の色 |
|
| align | 棒の位置 |
|
| data | dataframeを指定 |
|
引数はこのようになっており、xとheightだけ必須項目となっています。
棒グラフのplot
では実際に棒グラフを出力してみましょう。
まずは、ある集団の血液型をカウントした結果をplotしてみましょう。
サンプルデータを作るところから始めます。
|
1 2 3 4 |
# サンプルデータを作成 count = [14, 16, 10, 6] # 棒グラフをplot plt.bar(['A', 'B', 'O', 'AB'], count, data=df) |
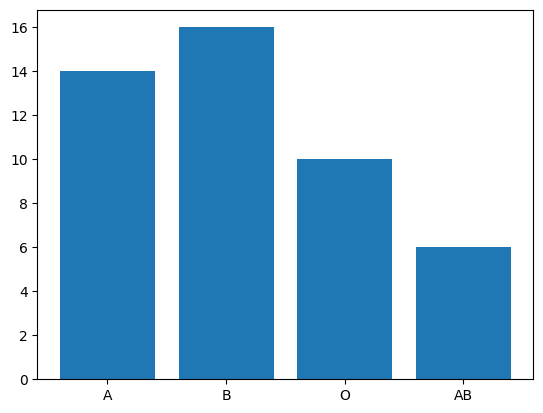
このように、引数には血液型のように直接リストで渡しても良いですし、countのように一回変数に入れてから渡しても大丈夫です。
ただ、データの個数は同じでないとエラーになってしまいますので、その点だけ注意しましょう。
また、他にもカテゴリーごとの平均値を出してplotすることも多いです。
例えば、先ほどのtipsデータの場合ですと、性別毎のtotal_bill(お会計額)の平均値を出してみると、それぞれの特長が見えてくるかもしれません。
↓のように、性別毎の平均値を出してからplotしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
# sexカラムに入っている値をユニーク化 sex = df['sex'].unique() # maleとfemaleのtotal_billの平均値を出す mean = [] mean.append(df[df['sex']=='Female']['total_bill'].mean()) mean.append(df[df['sex']=='Male']['total_bill'].mean()) # heightを平均値にしてplot plt.bar(sex, mean) |
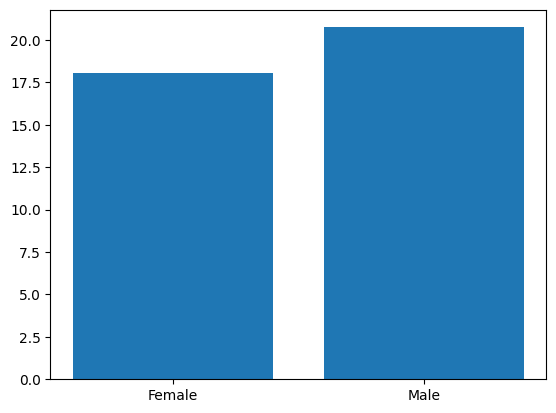
棒グラフの見え方を変える
colorやwidthを使う事で、グラフの見え方を変えることができます。
|
1 2 3 4 |
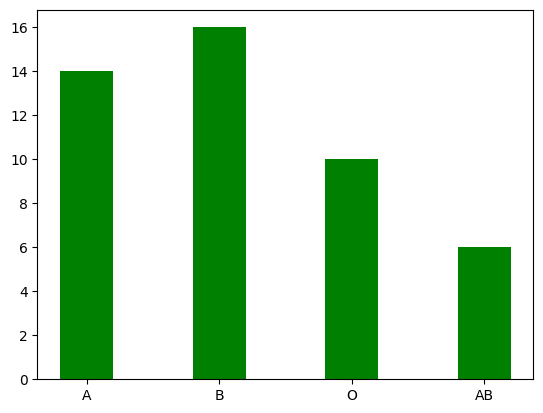
# サンプルデータを作成 count = [14, 16, 10, 6] # 棒グラフをplot plt.bar(['A', 'B', 'O', 'AB'], count, color='green', width=0.4, data=df) |
棒グラフに付属情報を追加する
棒グラフでもタイトルをつけたり、ラベルを付けたりができます。
また、グリッドも追加してさらに綺麗なグラフを作りましょう。
今までと同じく、下記のコマンドを追加するだけでできます。
- plt.title(‘タイトル名’)
- plt.xlabel(‘x軸のラベル’)
- plt.ylabel(‘y軸のラベル’)
|
1 2 3 4 5 6 7 |
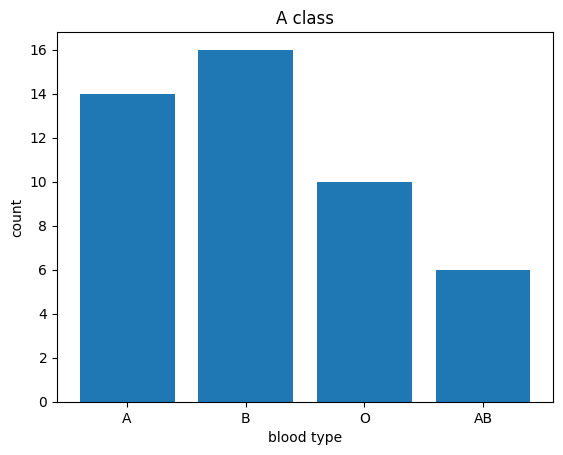
# サンプルデータを作成 count = [14, 16, 10, 6] # 棒グラフをplot plt.bar(['A', 'B', 'O', 'AB'], count, data=df) plt.title('A class') plt.xlabel('blood type') plt.ylabel('count') |
積み上げ棒グラフをplot
棒グラフでも積み上げ形式で表示する事ができます。
その際使うのがbottomです。
流れとしては、plotする2つのheightを作り、一個目はそのままplotします。
2個目にbottomに一個目の値を指定して、一個目分浮かしたうえで2個目をplotします。
まぁ説明するのは難しいので、実際に見ていきましょう。
|
1 2 3 4 5 6 7 8 |
# サンプルデータを2つ作成 count1 = [14, 16, 10, 6] count2 = [7, 12, 6, 3] bloodtype = ['A', 'B', 'O', 'AB'] # 棒グラフをplot plt.bar(bloodtype, count1) plt.bar(bloodtype, count2, bottom=count1) |
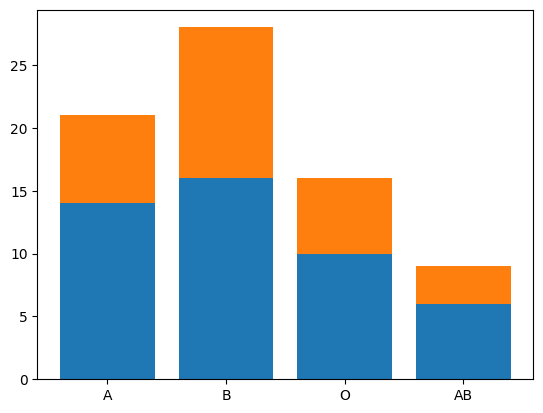
このようにして作成する事ができます。
こうなると、凡例が欲しくなりますよね?
下記のようにすることで追加できます。
|
1 2 3 4 5 6 7 8 9 10 11 |
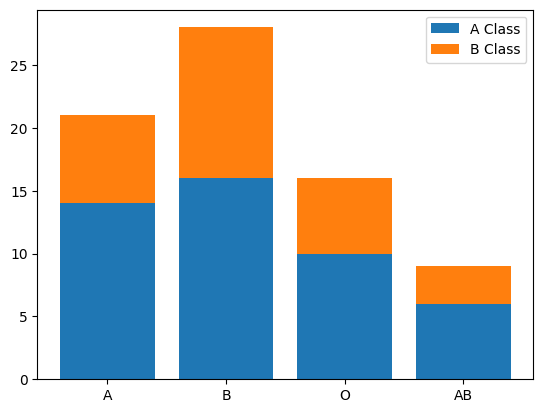
# サンプルデータを2つ作成 count1 = [14, 16, 10, 6] count2 = [7, 12, 6, 3] bloodtype = ['A', 'B', 'O', 'AB'] # 棒グラフをplot plot1 = plt.bar(bloodtype, count1) plot2 = plt.bar(bloodtype, count2, bottom=count1) # 凡例追加 plt.legend((plot1, plot2), ('A Class', 'B Class')) |
まとめ
今回も大分ボリューミーな内容でしたね。
ヒストグラムや棒グラフは実際の現場でも必ず出てくるものですので、その特徴をしっかりと押さえて使いましょう。
- ヒストグラム:連続値に対して使う
- 棒グラフ:カテゴリカルな値に使う
また、全てを覚える必要はないです。
まずは基本だけを抑えて、あとは何が出来るのかを理解出来れば十分です。
実際に使うときは、チートシートやググりつつコードが書ければ問題ないです。
Work illustrations by Storyset











