

今回の講座ではmatplotlibのplt.scatter()を使って散布図を描画する方法を紹介します。
これも比較的簡単に作成することができますので、サクッとやっていきましょう!
今回の講座では、
- 散布図とは何か?
- plt.scatter()で散布図をplotする方法
コチラを紹介していきます。
散布図とは何か?
まずは散布図とは何かをしっかりと理解しましょう。
見たことはあるけど、一体何の為にあるのか理解していない人も多いです。
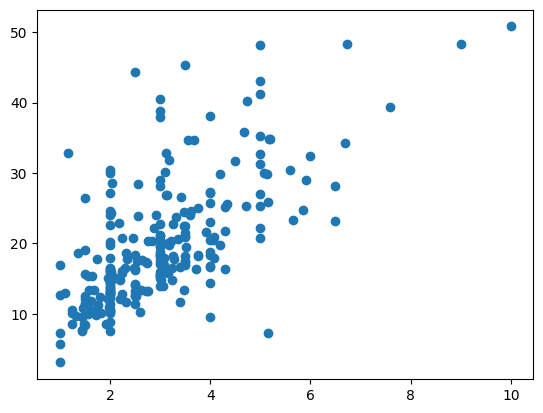
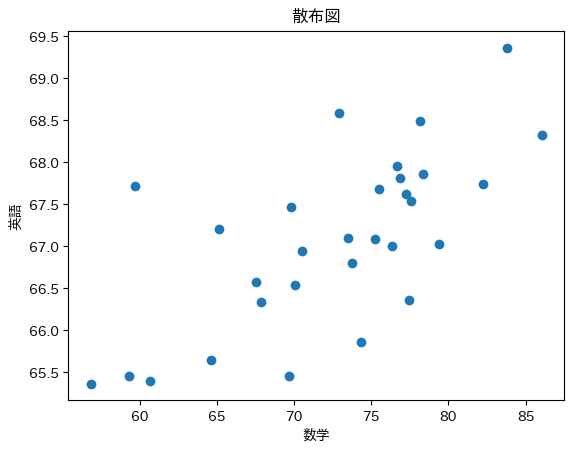
散布図とは、↑のように点が散らばっている図のことを言います。
散布図が表すもの
ではこれが何を表しているのかというと、
2つの項目の相関関係とその強弱を表しています。
例えば、売上高と広告費の関係性を調べたい場合、売上高を縦軸(y軸)、広告費を横軸(x軸)にプロットして、点の散らばり方を観察することで、両者に相関関係があるかどうかを判断することができます。
相関関係
相関関係には正の相関と負の相関があり、散布図から読みとることができます。
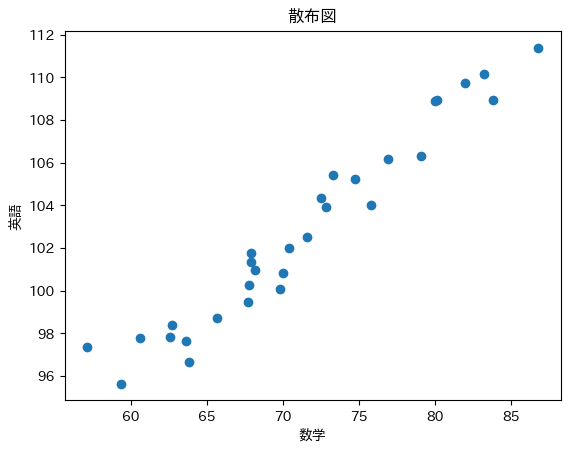
このように、右肩上がり散布図の場合は正の相関です。
一方の数値が上がると、もう一方の数値が上がります。
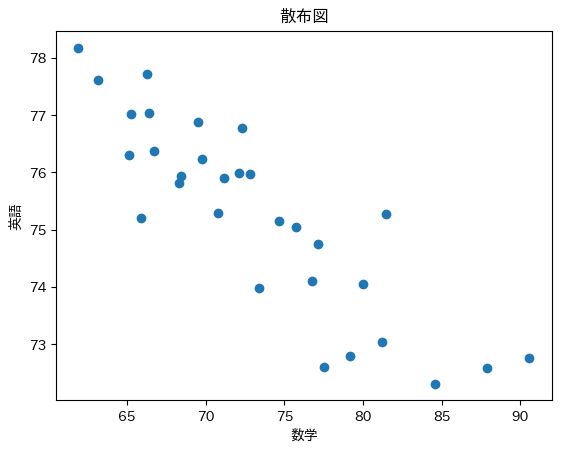
逆に右肩下がりの場合は負の相関です。
一方の数値が上がると、もう一方の数値が下がります。
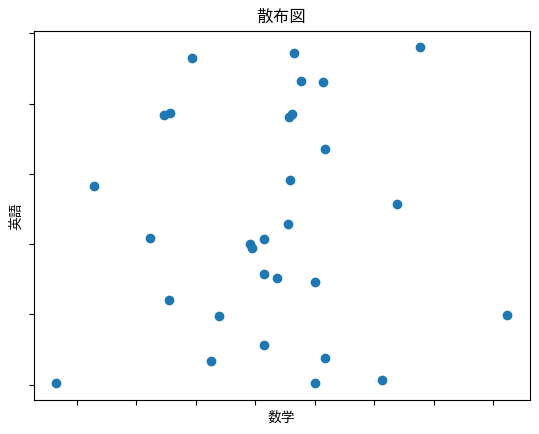
最後に相関が見られない物もあります。
これは無相関と呼ばれ、一方の数値が上下しても、もう一方には影響を与えないものです。
相関の強弱
散布図は相関関係だけではなく、相関の強弱も表します。
例えば、↓のように点がまとまっていたら相関が強いことを表しています。
逆に、↓のように点が散らばっている場合は相関が弱いことを表しています。
scatter()の使い方
では実際にscatter()で散布図を描画する方法を見ていきましょう。
一番シンプルな使い方としては↓になります。
- plt.scatter(x, y)
散布図をplot
では実際に散布図をplotしてみましょう。
まず2通りのやり方でplotします。
- ランダムデータを作成してから
- dataframeを作成してから
まずはランダムデータを作成してからです。
numpyを使って生成します。
|
1 2 3 4 5 6 7 8 9 |
import numpy as np import matplotlib.pyplot as plt # 50個のランダムデータを作成 x = np.random.rand(50) y = np.random.rand(50) # 散布図をplot plt.scatter(x, y) |
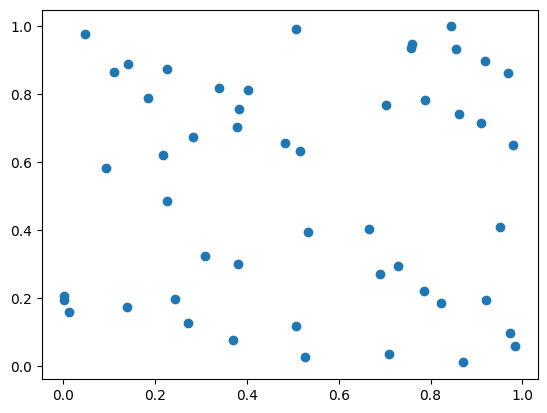
無事50個の点がある散布図が出来ました。
今回はランダムデータを生成しているので、点が全体に散らばっており、当たり前ですが無相関の形をしていますね!
注意点としてxとyのデータの数は一緒でないといけません。
個数が違うとエラーになります。
dataframeから作成
続いて、pandasのdataframe形式から作成する方法を見ていきましょう。
せっかくですので、「iris」という有名なサンプルデータをもとにplotしましょう!
まずサンプルデータをインポートしますが、この際seabornを使います。
細かい説明は省きますが、↓のコマンドでirisデータをインポートして、dfに入れています。
|
1 2 3 4 5 |
import pandas as pd import seaborn as sns # irisデータをdataframeにする df = sns.load_dataset('iris') |
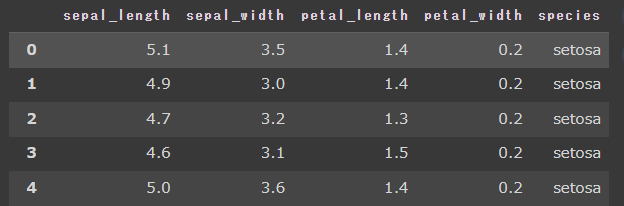
これでdataframeにすることが出来ました。
ちなみにirisのデータは以下の5カラムになっています。
- sepal_length : ガクの長さ
- sepal_width : ガクの幅
- petal_length : 花弁の長さ
- petal_width : 花弁の幅
- species : アヤメの種類
はなのガク・花弁の大きさからアヤメの種類を推測するのによく使われています。
ではこのsepal_lengthをx軸、petal_lengthをy軸に指定してplotしてみましょう。
↓のように指定します。
- plt.scatter(x, y, data=dataframe)
scatter()のxとyにはそのままカラム名を指定し、data引数にdataframeを渡してあげます。
|
1 |
plt.scatter('sepal_length', 'petal_length', data=df) |
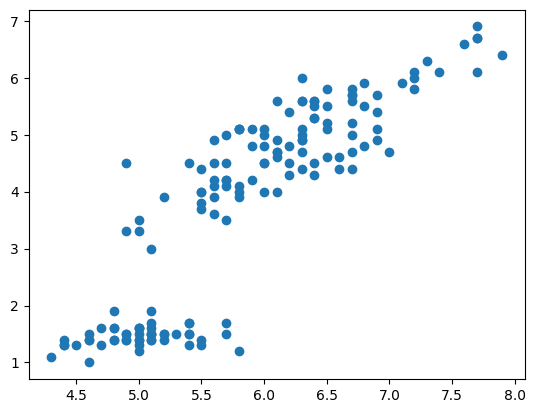
ちなみに↓のように書いても同じ結果になります。
|
1 |
plt.scatter(df['sepal_length'], df['petal_length']) |
散布図から、少しいびつですが、右肩上がりになっているので正の相関があることが分かりますね!
また、散らばりも少なくまとまっているので、強い相関があることが分かります。
scatter()で色々な引数を指定する
まずはシンプルな散布図をplotする方法が分かったと思います。
scatter()でも引数に色々指定することで、グラフを綺麗にすることが可能です。
主要なものとして、↓があります。
|
1 2 3 |
lt.scatter(x, y, s=None, c=None, marker=None, alpha=None, linewidths=None, edgecolors=None, data=None) |
| 引数 | 説明 | 詳細 |
| s | 点のサイズ |
|
| c | 点の色 |
|
| marker | 点の形 |
|
| alpha | 透明度 |
|
| linewidths | 線の太さ |
|
| edgecolors | 線の色 |
|
| data | dataframeを指定 |
|
マーカーを変更する
まずはマーカー(点)の色や大きさの変更をしてみます。
また、マーカーの形はmarker=’v’などの形で指定できますが、ほぼデフォルトの〇で使うことがほとんどでしょう。
|
1 |
plt.scatter('sepal_length', 'petal_length', s=100, c='red', marker='v', data=df) |
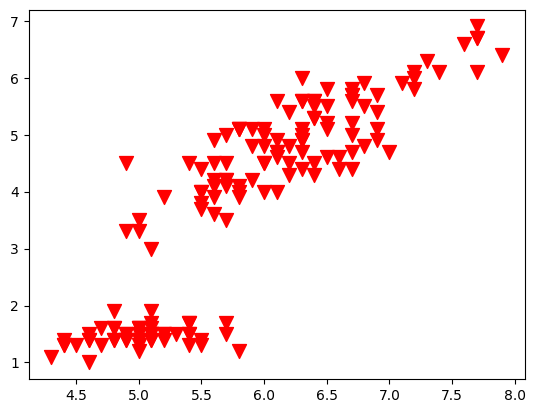
このように、マーカーの大きさ、色、形の変更をすることが可能です。
また、マーカーのサイズはカラム名で指定することもできます。
その場合は指定したカラムの値によってマーカーの大きさが変化しますので、より深い情報をplotすることができます。
|
1 |
plt.scatter('sepal_length', 'petal_length', s='petal_width', data=df) |
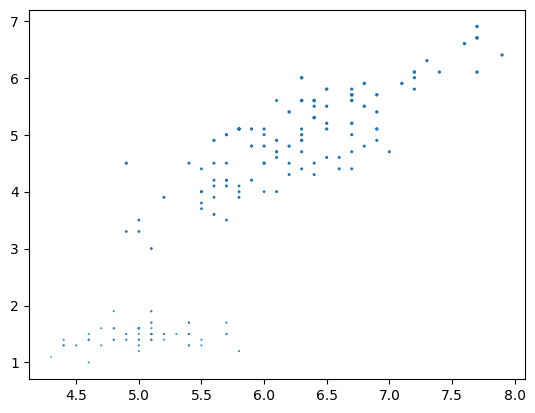
このように指定すると、petal_widthの値によって大きさが変化します。
alphaで透明度を指定
alphaで数字を指定すると、透明度を設定することができます。
データ数が多かったりで、点が被ってしまうと分布が見辛いですよね。
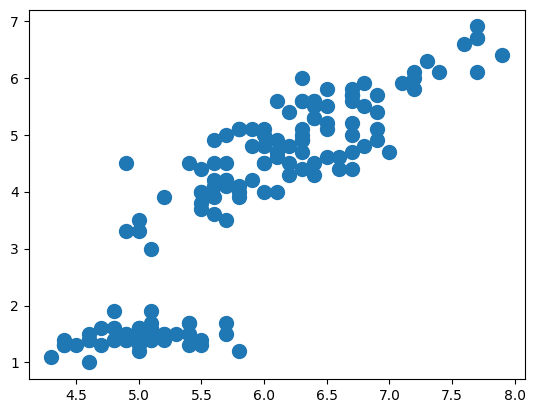
このように、ぐちゃっとした感じになってしまいます。
そんな時はalphaで指定してあげましょう!
|
1 2 |
# alphaで透明度を設定 plt.scatter('sepal_length', 'petal_length', s=100, alpha=0.5, data=df) |
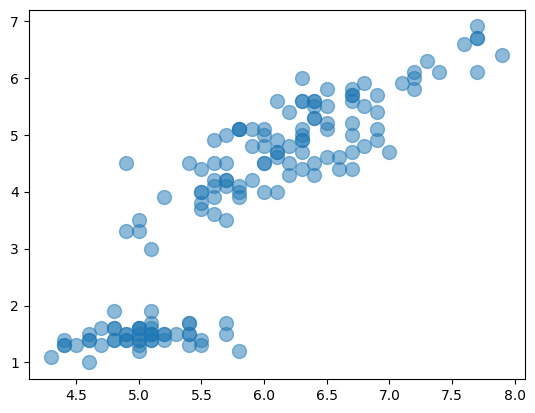
このようにすることで、重なり具合も視覚的に把握することができます。
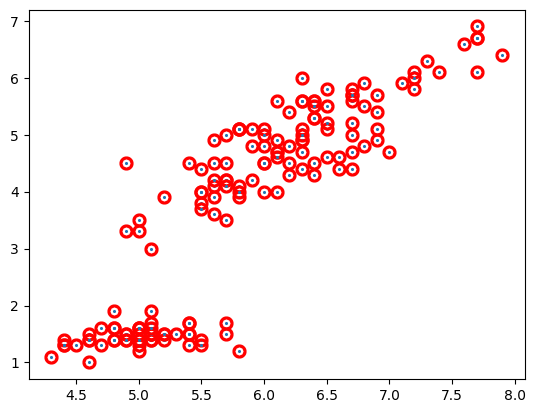
線の設定
線と言われてもなんのことか分からないと思うので、実際にやってみましょう。
|
1 |
plt.scatter('sepal_length', 'petal_length', s=5 ,linewidths=8, edgecolors='red', data=df) |
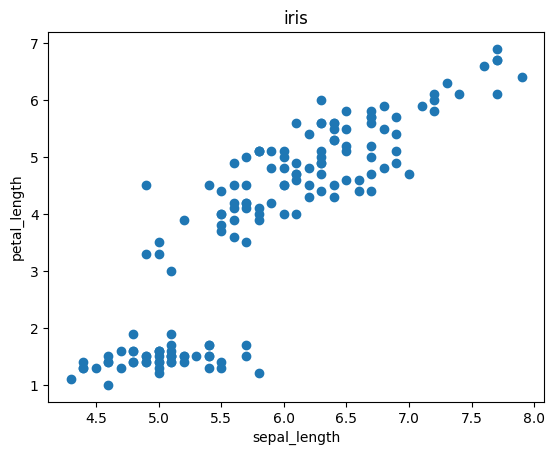
scatter()で付帯情報をつける
散布図にももちろんタイトル名やラベルを付けることができます。
さっそくやってみましょう。
今まで通り、↓で指定できます。
- plt.xlabel():x軸にラベル付け
- plt.ylabel():y軸にラベル付け
- plt.title():グラフのタイトルをつける
|
1 2 3 4 |
plt.scatter('sepal_length', 'petal_length', data=df) plt.xlabel('sepal_length') plt.ylabel('petal_length') plt.title('iris') |
散布図をカテゴリー値ごとに色分け
続いてもう一歩踏み込んだ使い方をしてみましょう。
散布図をplotするだけでなく、speciesカラムのカテゴリーごとに色分けをして見やすくしてみます。speciesは以下の3つの種類が入っています。
- setosa
- versicolor
- virginica
色々な方法がありますが、今回は理解しやすいように、種類ごとにdataframeを分け、それを色を変えてplotします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# speciesの種類ごとにdataframe化 setosa_df =df[df['species'] == 'setosa'] versicolor_df =df[df['species'] == 'versicolor'] virginica_df =df[df['species'] == 'virginica'] # それぞれのデータをラベルを付けてplot plt.scatter('sepal_length', 'petal_length', data=setosa_df, label='setosa') plt.scatter('sepal_length', 'petal_length', data=versicolor_df, label='versicolor') plt.scatter('sepal_length', 'petal_length', data=virginica_df, label='virginica') # タイトル・ラベル付け plt.xlabel('sepal_length') plt.ylabel('petal_length') plt.title('iris') plt.legend() |
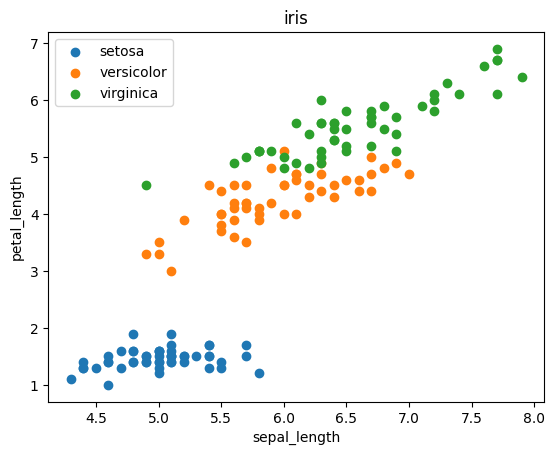
かなり綺麗に、speciesの種類によってデータが分かれているのが分かりますね!
このようにすると、x軸とy軸の相関だけでなく、speciesを足した相関関係を視覚化することができます。
Work illustrations by Storyset











