

今回はpandasチュートリアルの八回目になっています。
前回のがまだという方は↓の記事を参照ください。
【python】データ分析のためのpandasの使い方⑦:良く使う関数!
データ分析をやる上で、色々なデータフレームを結合するシーンは多いと思います。
しかし、引数が複雑で思った通りに結合出来ないなんて事も多いです。
そんな方のために、今回は表結合の方法をマルっと解説していきます。
全てサンプルコードを記載してあります。各々のpythonの環境で実際に手を動かしながら読み進めていってください。
サクッとやりたい方は、google colaboratoryが簡単でおすすめです。
表結合はmarge()とconcat()
表結合とは単純にデータフレーム同士を結合させ、新しいデータフレームを作る事です。
データサイエンスでは何かと使う機会が多い手法です。
Pandasでは、複数のデータフレームを結合する方法として、mergeとconcatの2つの関数があります。
簡単に説明しますね。
- merge : 指定したキーに基づいて2つのデータフレームを結合する関数で、SQLのJOINに似た操作ができます。
- concat : 縦または横方向に複数のデータフレームを単純に結合する関数です。
したがって、mergeは複数のデータフレームを、キーに基づいて結合するために使用され、concatは複数のデータフレームを縦または横方向に単純にサクッと結合するために使用されます。
それぞれの使い方を見ていきましょう。
concat()でデータフレームを結合
concat()関数を使用すると、データフレームを縦方向または横方向に連結することができます。
縦方向の場合、データフレームは上下に結合され、横方向の場合、データフレームは左右に結合されます。
concat()の使い方
以下は、concat()関数を使用して2つのデータフレームを横方向に結合する例です。
まずはサンプルのデータフレームを2つ作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
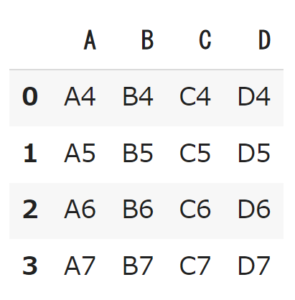
import pandas as pd # サンプルデータの作成 df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'], 'B': ['B4', 'B5', 'B6', 'B7'], 'C': ['C4', 'C5', 'C6', 'C7'], 'D': ['D4', 'D5', 'D6', 'D7']}) |
作成したテーブルの中身を見てみましょう。
df1->
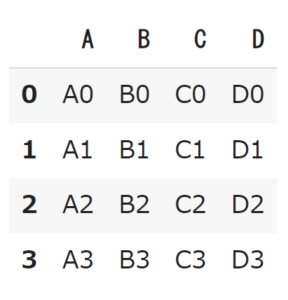
df2->
concat()で横結合
ではこれをまずは横に結合したいと思います。
concat()の引数として、結合したいデータフレームをリストで渡し、axis=1と指定するだけです。
|
1 2 |
# データフレームの横方向結合 pd.concat([df1, df2], axis=1) |
->

この様に、単純に横に結合したデータフレームができました。
concat()で縦結合
では続いて縦結合をしてみましょう。
axis=0とするだけですので非常に簡単です。
|
1 2 |
# データフレームの縦方向結合 pd.concat([df1, df2], axis=0) |

このように、concat()ではサクッとデータフレームを結合したい時に簡単に使えます。
また、concat()関数では、結合するデータフレームに対して、いくつかのパラメータを指定することができます。
例えば、ignore_indexパラメータをTrueに設定すると、元のインデックスを無視して、新しい連番のインデックスが作成されます。
|
1 2 |
# indexの振り直し pd.concat([df1, df2], axis=0, ignore_index=True) |

indexが0~7まで振り直されました。
merge()でデータフレームを結合
merge()はconcat()と比べると、キーを基に結合出来るため、より自由度の高いデータフレームを作る事ができます。
私も実務で使うのはほぼほぼmerge()です。
merge()の引数
複雑な処理が出来るため、引数も多いです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
merge(left: DataFrame | Series, right: DataFrame | Series, how: str='inner', on: IndexLabel | None=None, left_on: IndexLabel | None=None, right_on: IndexLabel | None=None, left_index: bool=False, right_index: bool=False, sort: bool=False, suffixes: Suffixes=('_x', '_y'), copy: bool=True, indicator: bool=False, validate: str | None=None) |
このように、様々な引数がありますが、全てを覚える必要はありません。
主要なものだけ解説していきます。
left: マージする左側のデータフレームright: マージする右側のデータフレームhow: 結合方法。inner、outer、left、rightの4つのオプションがあります。デフォルトはinnerです。on: マージするキー列(列名)またはキー列のリスト。左側と右側のデータフレームのどちらにも存在する列を指定します。left_on: マージする左側のデータフレームのキー列(列名)right_on: マージする右側のデータフレームのキー列(列名)suffixes: カラム名が重複した場合に使用される、接尾辞を指定します。リスト形式で指定することができます。デフォルトでは、左側の接尾辞が_x、右側の接尾辞が_yになります。
leftとrightについて
まずは結合の元となるデータフレームをleftとrightで指定します。
そのまま、leftで指定したdfが左側にきて、rightで指定したdfが右側にきます。
例えば、一方には顧客の名前とIDを入れたdf_customersを作り、もう一方のデータフレームには顧客のIDと注文金額が含まれているdf_ordersを作ります。
そして、df_customersをleft、df_ordersをrightにして、顧客IDをキーに結合してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import pandas as pd # 顧客情報のデータフレーム df_customers = pd.DataFrame({ 'customer_id': [1, 2, 3, 4, 5], 'name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'] }) # 注文情報のデータフレーム df_orders = pd.DataFrame({ 'customer_id': [1, 2, 2, 3, 6], 'amount': [100, 50, 75, 200, 150] }) # 顧客情報と注文情報を結合する df_merged = pd.merge(df_customers, df_orders, on='customer_id') df_merged |
結果として下記のデータフレームが出来ます。
|
1 2 3 4 5 |
customer_id name amount 0 1 Alice 100 1 2 Bob 50 2 2 Bob 75 3 3 Charlie 200 |
leftとrightの指定を逆にすると、amountが左側に来てnameが右側に来ます。
howについて
howに指定する値としては、inner、outer、left、rightがあります。
以下は、how引数の説明です。
inner: 内部結合。両方のデータフレームに共通するキーのみを残して結合します。outer: 外部結合。どちらか一方にだけあるキーも含めて結合します。left: 左外部結合。左側のデータフレームにあるキーを基準に、右側のデータフレームを結合します。right: 右外部結合。右側のデータフレームにあるキーを基準に、左側のデータフレームを結合します。
innner
innerでは両テーブルにあるキー項目のみ残ります。先ほどのデータフレームですと、顧客IDが両dfにある場合のみ残ります。
|
1 2 |
df = pd.merge(df_customers, df_orders, on='customer_id', how='inner') print(df) |
そのためcustomer_idが1,2,3のレコードしか残りません。
|
1 2 3 4 5 |
customer_id name amount 0 1 Alice 100 1 2 Bob 50 2 2 Bob 75 3 3 Charlie 200 |
outerについて
逆にouterの場合はどちらか一方にしかないキーも残ります。
|
1 2 |
df = pd.merge(df_customers, df_orders, on='customer_id', how='outer') print(df) |
|
1 2 3 4 5 6 7 8 |
customer_id name amount 0 1 Alice 100.0 1 2 Bob 50.0 2 2 Bob 75.0 3 3 Charlie 200.0 4 4 David NaN 5 5 Emily NaN 6 6 NaN 150.0 |
値が無い部分は欠損値のNaNが入ります。
left・rightについて
例えばleftとした場合は、leftに指定したデータフレームのキー項目全てと、それと合致するright側のレコードだけが結合されます。
|
1 2 |
df = pd.merge(df_customers, df_orders, on='customer_id', how='left') print(df) |
結果↓のdfができます。
|
1 2 3 4 5 6 7 |
customer_id name amount 0 1 Alice 100.0 1 2 Bob 50.0 2 2 Bob 75.0 3 3 Charlie 200.0 4 4 David NaN 5 5 Emily NaN |
このように、left側(df_customers)にcustomer_idの1~5に関するレコードは両テーブルとも残りますが、rightにしかないcustomer_idが6のレコードは除外されます。
howの指定をrightにすると全く逆の事が起こります。
でも基本的には、わざわざrightを指定する事はあまりないと思います。
だったらleftで指定した方が分かりやすいので。
onについて
on引数は、結合する2つのデータフレームに共通する列名を指定するために使用されます。これにより、列名をキーとして2つのデータフレームが結合されます。
実は先ほどからcustomer_idをキーにするために、「on=’customer_id’」として使っていました。
結合するキーとなるカラムを指定します。
left_on、right_onについて
こちらも使い方はonと一緒なのですが、2つのデータフレームで結合したいキーのカラム名が違う場合に使います。
例えば、一方はkeyでもう一方はkey2となっていたらonは使えません。そんな時に使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# データフレーム1の作成 df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]}) # データフレーム2の作成 df2 = pd.DataFrame({'key2': ['A', 'B', 'E', 'F'], 'value2': [5, 6, 7, 8]}) # left_onとright_onを使用して2つのデータフレームをマージ merged_df = pd.merge(df1, df2, left_on='key', right_on='key2', how='inner') print(merged_df) |
結果、↓のdfができます。
|
1 2 3 |
key value key2 value2 0 A 1 A 5 1 B 2 B 6 |
howをinnerにしているので、df1のkeyカラムとdf2のkey2カラムの両方にある値のA、Bに関するレコードのみが結合されました。
howをouterにすると2つのdfの全てのレコードが結合されます。
suffixesとは?
suffixesは、重複する列名がある場合に、それらの列名を区別するために接尾辞を付けることができます。
具体的には、2つのデータフレームをマージするとき、重複する列名がある場合、suffixesを使用してそれぞれの列名に接尾辞を追加することができます。
デフォルトでは、接尾辞は _x と _y が使われますが、suffixes引数を使用して独自の接尾辞を指定することもできます。
例えば、以下のような2つのデータフレームがあるとします。
|
1 2 |
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]}) df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]}) |
これらのデータフレームを key 列でマージする場合、suffixes引数を使用して、接尾辞を指定できます。
|
1 2 |
merged_df = pd.merge(df1, df2, on='key', how='outer', suffixes=('_left', '_right')) print(merged_df) |
結果↓の接頭辞が付いたdfが出来ました。
|
1 2 3 4 5 6 7 |
key value_left value_right 0 A 1.0 NaN 1 B 2.0 5.0 2 C 3.0 NaN 3 D 4.0 6.0 4 E NaN 7.0 5 F NaN 8.0 |
まとめ
いかがでしたでしょうか?
結合と言っても様々な方法があり、引数も多いためなかなか難しかったと思います。
特にhowでどの様に結合するのか?onでどのカラムをキーに結合するのか?などは重要になってきますので、どのような挙動になるのかを理解しておきましょう~。
今すぐに全てを覚える必要はないので、実践の中で色々試しながら学んでいきましょう。











