

今回はpandasチュートリアルの八回目になっています。
前回のがまだという方は↓の記事を参照ください。
【python】データ分析のためのpandasの使い方⑧:mergeとconcat
今までにデータフレームに対して結合したり、カラム削除をしたり追加したりと言った事を学んできたと思います。
そんな、処理したデータフレームをファイルに保存したくなりますよね?
そんな時に使うのがto_csv()です。
データ分析をする上で絶対に必要になってきますので、しっかりと身に着けましょう。
全てサンプルコードを記載してあります。各々のpythonの環境で実際に手を動かしながら読み進めていってください。
サクッとやりたい方は、google colaboratoryが簡単でおすすめです。
to_csv()とは?
Pythonのpandasライブラリには、データをCSVファイルとして保存するためのto_csv()関数があります。to_csv()関数は、DataFrameオブジェクトをCSVファイルとして書き込むことができます。
要は、自分で作成したデータフレームをファイルに保存する関数です。
ちなみにto_csvとなっていますが、csv形式だけでなくtsvなど様々な拡張子で保存する事もできます。
ただデータサイエンティストの場合はほぼほぼcsvを使う事が多いと思います。
to_csvの基本的な使い方
ではさっそく使い方を見ていきましょう。
そのためにはサンプルデータを用意しましょう。
前にも使ったseabornのtipsデータを使ってみましょう。
データを読み込んだらsizeが6のレコードだけを抽出しましょう。
|
1 2 3 4 5 6 |
import pandas as pd import seaborn as sns df = sns.load_dataset('tips') df = df[df['size'] == 6] df |
そうすると下記の様に、sizeが6のレコードだけが残ったと思います。
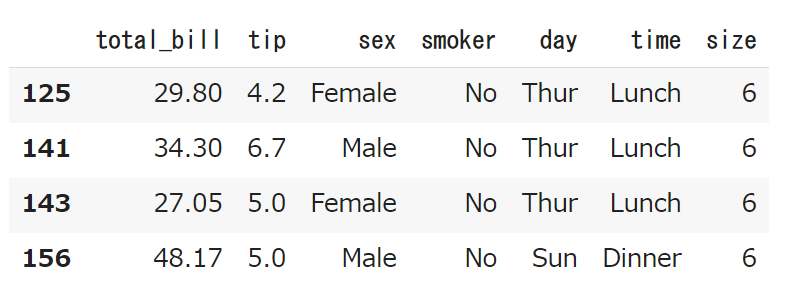
これをtips_sample.csvという名前で保存してみましょう。
|
1 |
df.to_csv('tips_sample.csv') |
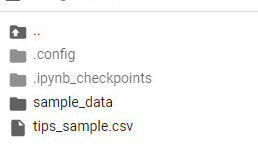
簡単ですね、そうすると下記の様に新しいファイルが出来たと思います。
ちなみに、別のディレクトリに保存したい場合などは、’~/tips_sample.csv’のように、~の部分に任意のパスを指定すると、そこに保存する事ができます。
作成したファイルを読み込んでみよう
では今度はこの作成したファイルをread_csvで読みこんでみましょう。
|
1 2 |
df = pd.read_csv(('tips_sample.csv')) df |
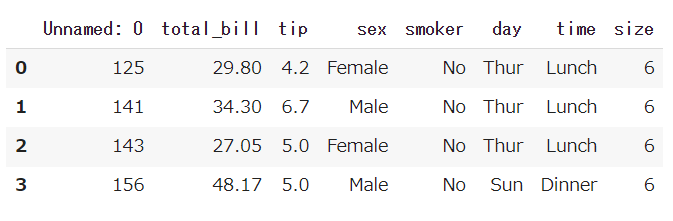
無事読みこむ事が出来ました。
しかし、よ~く見てみると「Unnamed:0」という謎のカラムが追加されていますね!
中を見てみると0~3のindexが入っています。
これは邪魔ですね~indexが必要な場合はそんなにないので要らないと思います。
そんな時は、to_csvする時に引数でindex=Falseと指定してあげれば大丈夫です。
|
1 2 3 4 5 6 |
# もう一度tipsデータからdfを作成 df = sns.load_dataset('tips') df = df[df['size'] == 6] # indexを削除 df.to_csv('tips_sample.csv', index=False) |
これで無事にindexが入らずにすみました。
to_csv()で使う引数
index以外にもto_csv()では様々な引数があり、細かな設定をする事ができます。
数が非常に多いので、主要なものだけ解説します。
sep: CSVファイルの列の区切り文字を指定します。デフォルトは,です。encoding: CSVファイルのエンコーディングを指定します。デフォルトはUTF-8です。mode: ファイル書き込みモードを指定します。デフォルトはwで、上書きモードです。date_format: 日付データを書き込む際のフォーマットを指定します。
sepについて
sepは、出力するCSVファイルのセパレーター(区切り文字)を指定するための引数です。CSVファイルは、各列の値がカンマ,やタブ\tで区切られていますが、sep引数を使うことで、カンマ以外の区切り文字を使うことができます。
例えば、sep='\t'と指定することで、タブ区切りのtsvファイルを出力することができます。また、sep='|'と指定することで、パイプ|で区切られたpipeファイルを出力することもできます。
|
1 2 3 4 5 |
# タブ区切りのCSVファイルを出力 df.to_csv('tips_sample.tsv', sep='\t', index=False) # パイプ区切りのCSVファイルを出力 df.to_csv('tips_sample.pipe', sep='|', index=False) |
encordingについて
encodingは、CSVファイルに書き込むときに使用する文字エンコーディングを指定するための引数です。CSVファイルはテキストファイルの一種であり、文字エンコーディングによっては日本語や他の多言語が正しく書き込まれない場合があります。
encoding引数は、Pythonがサポートする文字エンコーディングのいずれかを指定することができます。一般的なエンコーディングとしては、UTF-8、Shift-JIS、EUC-JPなどがあります。
たとえば、UTF-8でCSVファイルを書き込む場合は、以下のようにencoding='utf-8'を引数に指定します。
|
1 2 |
# utf-8 df.to_csv('tips_sample.csv', encoding='utf-8', index=False) |
デフォルトでは、encoding引数は’utf-8’に設定されていますが、必要に応じて他のエンコーディングに変更することができます。
modeについて
to_csv()の引数であるmodeは、書き込みモードを指定するための引数です。デフォルトでは、’w’(新しいファイルを作成して書き込む)になっていますが、他にも以下のようなオプションがあります。
- ‘w’:新規フィルの作成
- ‘a’:既存のファイルに追記する
- ‘x’:新しいファイルを作成して書き込むが、既存のファイルがある場合はエラーを発生させる
- ‘b’:バイナリーモードでファイルを書き込む
たとえば、既存のファイルに追記する場合は、以下のように書くことができます。
|
1 |
df.to_csv('tips_sample.csv', mode='a', index=False) |
またxを指定すると、既存のファイル名がある場合にはエラーを発生して書き込めなくなります。
|
1 2 |
# x指定だとエラーが発生する df.to_csv('tips_sample.csv', mode='x', index=False) |

このように、Filse existsと既存ファイルがあるのでエラーになってしまいます。
data_formatについて
date_format引数は、日時オブジェクトを書き出す際に使用される書式を指定するための引数です。
デフォルトではNoneとなっており、日時オブジェクトはISO8601の書式で書き出されます。
具体的には、以下のように使用します。
まずは日付データのあるdfを作成します。
|
1 2 3 4 5 6 7 |
import pandas as pd import datetime df = pd.DataFrame({'date': [datetime.datetime(2022, 1, 1, 0, 0), datetime.datetime(2022, 1, 2, 0, 0)], 'value': [100, 200]}) df |
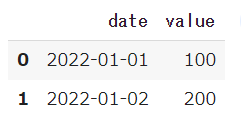
この様な日付表記のdfが出来ました。
これを日付表記を指定して書き出し、読み込んでみてみましょう!
|
1 2 3 4 |
# date_formatを指定して書き出し df.to_csv('sample.csv', date_format='%Y/%m/%d %H:%M:%S', index=False) # 書き出したファイルを読み込み pd.read_csv('sample.csv') |
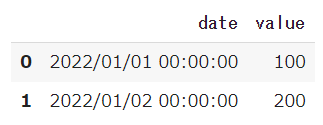
このように、マイクロ秒まで入る日付表記になりました。
まとめ
いかがでしたでしょうか?
to_csvを使う事で、ファイルの書き出しができます。
その際に、拡張子の指定であったり文字エンコーディングの指定をする事で、様々な設定ができます。
全てを一気に覚えるのは大変なので、見返しながら様々な設定をしてみてください。











