

ど~も!データサイエンティストのえいせいです!
今回はデータ分析をエクセルで行っている方必見!Pythonでできるデータ分析について、初心者の方でも分かるように、解説していきます。
今回の講座は主に以下のような方を対象にしています。
- 今までエクセルで分析してたけどもっとレベルアップしたい
- Pythonって触ったことないけど具体的にどんな事ができるの?
- グラフも作れるの?
正直Pythonで出来るデータ分析を全て紹介するとなると何十時間も掛かってしまいます。
ですので、今回はまずデータ分析においてPythonはどういった事ができるのか?
その点の紹介にフォーカスをあてて解説していきたいと思います。
Pythonでデータを読み込む
ではまずデータの読み込むところから始めましょう。
エクセルやCSVなどのファイルをPythonで読み込み、自由にいじれるようにしていきます。
google colaboratoryを使おう
まずPythonを使うためには使える環境の構築をしないといけません。
すでに環境が整っている方はそちらを使えば良いのですが、まだ無いという人は1から作るとなると少し手間ですので、google colaboratoryでサクッと試しましょう。
googleアカウントがあれば無料で実行できる環境が整っています。
しかもAI付なので、プロンプトで一瞬でコードを書いてくださるという神対応もしてくれます。
google colaboratory:こちらからアクセスすればすぐに使えます!
sampleデータを読み込む
ではgooglecolaboratory上で実際にPythonを実行してみましょう。
まずはサンプルのデータセットを読み込むところからです。
|
1 2 3 4 5 6 7 8 |
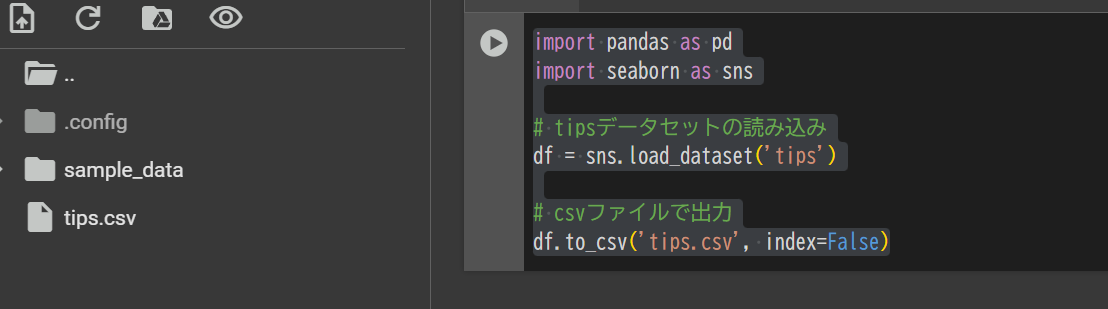
import pandas as pd import seaborn as sns # tipsデータセットの読み込み df = sns.load_dataset('tips') # csvファイルで出力 df.to_csv('tips.csv', index=False) |
上記のコードを実行してみましょう。
すると下記画像のように、tips.csvというファイルが作成されていると思います。
コードの説明としては以下の通りです。
- import ~ : Pythonで良く使うライブラリのpandasとseabornをインポートしています。
- pandas:データを表形式で色々と触れるようになる。データ分析において必須のライブラリです
- seaborn:本来はデータの可視化に使う。今回はサンプルのデータセットを読み込むために使用
- df = sns.load_dataset(‘tips’) :イコールの後の部分でtipsというサンプルデータをロードしており、それを変数dfに代入している
- dfはdataframeの略で一般的に使われる変数名
- df.csv() : dfをcsvに出力
これでまずはtips.csvファイルを作成する事ができました。
今度はこのcsvファイルを読み込んでdataframeを作成してみましょう。
|
1 2 |
# csvファイルからデータを読み込みdataframeを作成 df = pd.read_csv('tips.csv') |
これでまたdfにtipsデータセットがdataframeとして代入されました。
はい、今回は無駄にseabornからtipsデータセットを読み込み、それをファイルで出力。
またそのファイルを読み込んでからdfに代入という無駄な処理をしていますが、ライブラリ・ファイル、それぞれの読み込み方の練習だと思って実践してみましょう!
dataframeとは?
ここで疑問に思うのがdataframeとは何なのか?
本当にtipsデータセットがdfに代入されているの?という事でしょう。
せっかくですので、中身を見てみましょう。
|
1 2 |
# dfの先頭10列を表示 df.head(10) |
このように、する事で先頭10行が表示されます。
dfに対して.head()とする事で先頭から何行かを表示するかを指示できます。
また()の中に入れた値の分だけを表示してくれます。
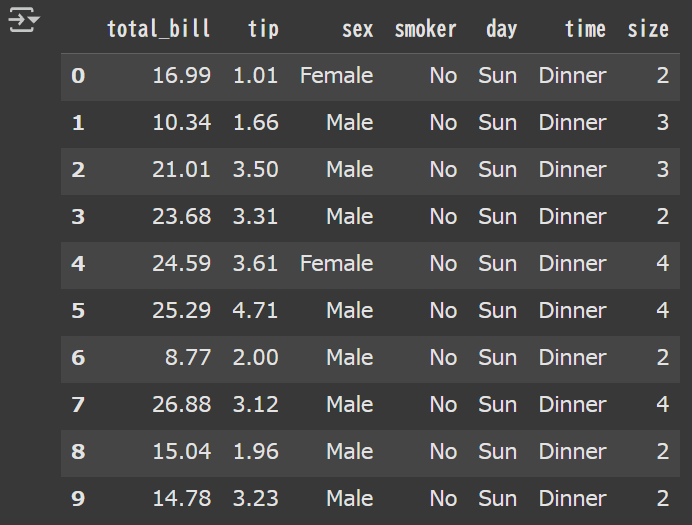 これがdataframeの正体です!
これがdataframeの正体です!
なんてことはありませんね~ほぼエクセルの表形式のものだと思って頂ければ大丈夫です!
ちなみにtipsデータセットはある架空のレストランのデータです。
それぞれのカラムの意味としては以下の通りです。
- total_bill:1グループあたりのお会計金額
- tip:チップの金額
- sex:性別
- smoker:喫煙の有無
- day:何曜日か?
- time:ディナーかランチか?
- size:人数
Pythonでのデータの基本操作
dataframeが作成されたところで続いて基本的な操作方法を見ていきましょう。
このdfを基に各種統計量を出したり、グループ毎の平均値などをサクッと求める事ができます。
データ分析において良く使う以下の処理を見ていきましょう!
- 平均値を出す
- 最大値、最小値を出す
- 相関係数を出す
- グループ毎の平均値を出す
どれもエクセルでも求める事は出来ますが、Pythonを使うとサクッと簡単に求める事が出来ます
Pythonで平均値、最大値、最小値を求める
まずは基本的なところから。
平均値、最大値、最小値を求めてみましょう。
tipsデータセットでは以下のカラムが数値カラムですので、それらを対象に求めてみます。
- total_bill
- tip
- size
ひとつずつ個別で求めることも出来るのですが、Pythonでは一括でそれらを簡単に求める事も出来ます。
|
1 |
df.describe() |
1行と非常にシンプルですね!
結果はこちらです。
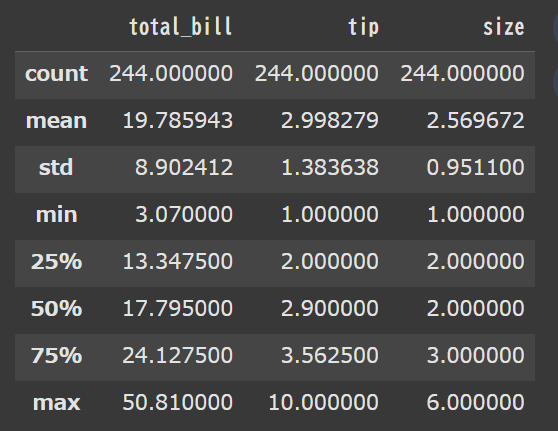
平均値や、最大値などだけでなく、良く使う統計量を一瞬で求める事が出来ました。
それぞれの意味としては下記の通りです。
- count:データの個数。欠損値(NaN)はカウントしない。
- mean:平均値
- std:標準偏差。sandard deviationの略
- min:最小値
- 25%:第1四分位数。データを小さい順に並べたとき、下から25%の位置にある値
- 50%:第2四分位数
- 75%:第3四分位数
- max:最大値
つまりtotal_billの平均値は19.79ドル位で、最小値は3ドル、最大値は50.8ドルという事が分かります。
tipとsizeに対しても同様ですね!
このように、Pythonを使う事で簡単に各種統計量を求める事が出来るのが嬉しいですね!
Pythonで相関係数を求める
では続いて相関係数を求めてみましょう!
相関係数とは2つのものの関係の強さを表す数字のことでした!
例えば、以下のようなものをイメージしてください。
- 気温が上がるとアイスの売り上げも上がる
- 身長が伸びると体重も増える
このように1方の値が変わると、もう1方にも影響を与える関係の強さを数値化したものが相関係数です。
値は-1から1までの間をとり、数字の意味としては以下のようになります。
| 相関係数 | 意味 |
| +1に近い |
|
| 0 |
|
| -1に近い |
|
この相関係数もPythonを使う事で簡単に求める事が出来ます。
|
1 2 |
# 相関係数を算出 df.corr(numeric_only=True) |
コードは1行と非常に簡単ですね!
これにより下記の結果を求める事ができました!
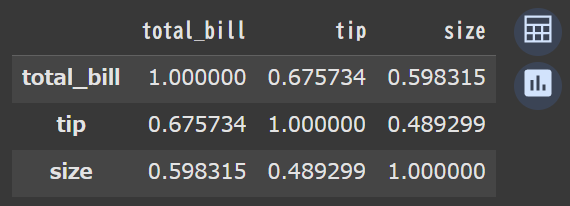
見方としては、total_billとtipの相関係数が0.675734とそこそこ強い正の相関がある事が分かります。
まぁ当たり前ですね、合計金額が多くなればチップの金額も増えるのが一般的でしょう。
また、sizeとtotal_billも0.598315とそこそこあります。
人数が増えれば合計金額が増えるのも納得ですね!
このようにPythonでは簡単に各カラム同士の相関係数を求める事が出来ます。
今回はカラムが少なかったですが、これが何十、何百とあるようなデータセットでも1行でサクッと求められるのは楽で良いですね!
グループ毎の平均値を求める
最後にグループ毎の平均値を求めてみましょう。
例えば、tipsデータセットはsexカラムがあり、male(男性)とfemale(女性)の値を持っています。
これをグループ化し、男性と女性のグループで、total_billの平均値に差があるのか確認したいって時もありますよね?
そんな時もPythonを使えばサクッと求める事ができます。
|
1 2 3 |
# sexカラムでグループ化し、各カラムの平均値を算出 df.groupby("sex").mean(numeric_only=True) |
このコードを実行してみましょう。
すると下記のように、maleとfemaleでtotal_billやtipのグループ毎の平均値を求める事ができました。
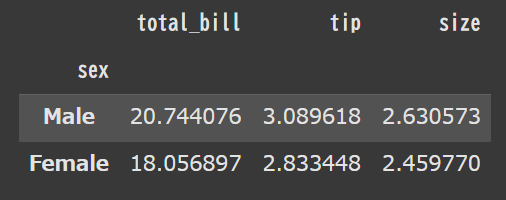
MaleとFemaleのtotal_billの平均値には若干の違いがある事が分かりました。
ただし、今回はサンプルデータなのでそもそもレコードが244しかないのでそこまでの信憑性はありません。
男女で有意に差があるとは言いづらいですね~!
この結果を見て、男性と女性に本当に差があるかを判断するにはPython×統計学を使えば判断する事も出来ます。
今回は時間の関係で割愛しますが、Pythonではそういった事も出来る事を覚えておいてください。
Pythonでの可視化
Pythonでは分析だけでなく、データを棒グラフや散布図などの各種グラフに可視化する事もできます。
有名なライブラリとしては以下のものがあります。
- matplotlib
- seaborn
これらを使うことで、下記のようなグラフを作成することができます。
ほんの一部ですが、この様なグラフを作る事ができます。
Pythonで棒グラフを作成
では実際にPythonで棒グラフを作成してみましょう。
先ほど求めた、sexカラムでグループ化したあとのtotal_billの平均値を使い、可視化してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import matplotlib.pyplot as plt # sexカラムでグループ化し、total_billの平均を計算 sex_bill_mean = df.groupby("sex")["total_bill"].mean() # 棒グラフで可視化 plt.figure(figsize=(8, 6)) sex_bill_mean.plot(kind='bar') plt.title('Average Total Bill by Sex') plt.xlabel('Sex') plt.ylabel('Average Total Bill') plt.xticks(rotation=0) # x軸ラベルの回転をなくす plt.show() |
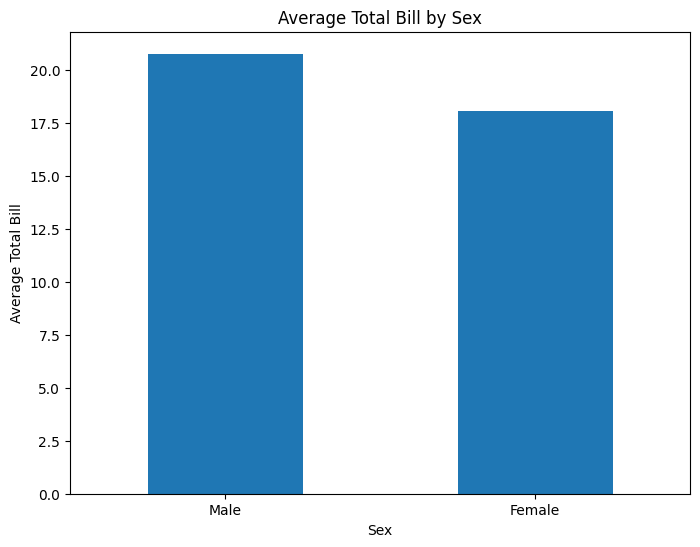
maleとfemaleでどれくらいtotal_billの平均値に差があるのかが、視覚的に分かりやすくなりました。
Pythonではグラフの色やx軸やy軸のラベル表記、グラフのタイトルなど様々な箇所を自分好みにカスタマイズする事もできます。
pairplotで一括表示
個人的に良く使うものとしてpairplotがあります。
これは複数のカラム同士の散布図やヒストグラムを一括で表示してくれる非常に便利な関数です。
ざっくりとしたイメージとしては、「多変量データの関係性をざっくり可視化するスーパーツール」と思ってください。
pairplotはseabornに含まれる関数ですので、seabornをimportしてから使います。
|
1 2 3 4 5 |
import seaborn as sns # ペアプロットを作成 sns.pairplot(df) plt.show() |
たったこれだけです。
これを実行すると下記の結果になります。
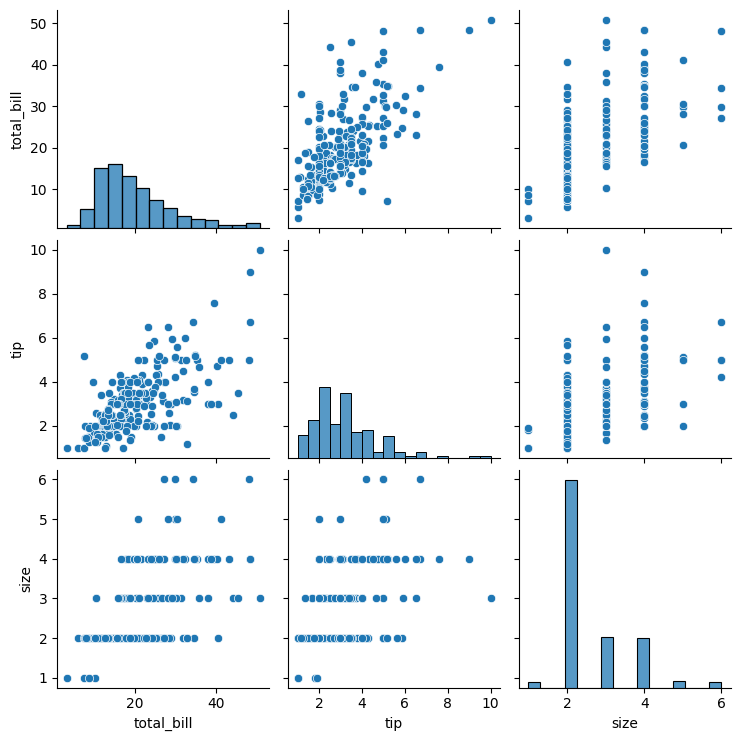
この様にする事で、各カラム同士の散布図とヒストグラムを一括で表示してくれます。
まず初めにデータセット全体の特長をつかみたい時に便利ですね~!
ただ注意点としては、カラム数が多いデータセットですと処理に時間が掛かります。
数百カラムあると、なかなか処理が終わらないといったことになりますので、その点注意です。
まとめ
いかがでしたでしょうか?
Pythonで出来るデータ分析入門という事で、データ分析における基礎的な使い方を紹介しました。
今回の内容を応用することで、まずはデータセットの特長をつかむ事ができると思います。
またPythonでさらに統計学を用いた各種分析や、因果推論・機械学習などより深い分析をすることもできるようになります。
是非Pythonを活用して、データ分析をより深めていきましょう!!












