

PandasはPythonのデータ解析ライブラリであり、データサイエンスを行うためには絶対に必要になってきます。
この記事ではpandasを扱う為の第一歩、データフレームの作成方法を紹介します。
データ分析に必要なtipsをもれなくお伝えしますので、是非ハンズオンで実践してみてください。
「pandas」とは
Pandasはエクセルの様な表形式のデータを扱うのに長けており、データのフィルタリング、変換、操作、集約などを簡単に実行できます。
具体的には以下の様な特長をもっています。
- データの読み込みと書き込みに対応しており、多くのファイル形式をサポートする。
- メモリ上でのデータの処理を効率化するため、高速である。
- 欠損値の処理やデータの集約など、多様なデータ操作に対応している。
対応しているファイル形式としては、CSV、Excel、JSONなど、多くのファイル形式をサポートしています。
つまり、
データ分析・機械学習を行うなら必須です!!
データフレームとシリーズとは?
覚えて欲しい事として、データフレームとシリーズがあります。
データフレームの特長
- データフレームは、2次元の表形式のデータを扱うことができます。n×n行列。
- 列ごとに異なるデータ型を持つことができます。
- 2次元の操作(列選択、列の削除、列の追加、列の名前の変更、列のデータ型の変更、行選択、行の削除、行の追加など)を行うことができます。
データフレームはエクセルのテーブルをイメージすると分かりやすいと思います。
シリーズの特長
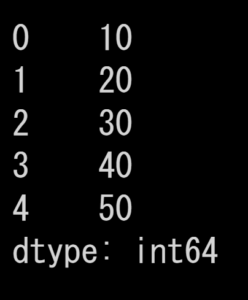
- シリーズは、1次元の配列のような形式で、単一の列を扱います。
- シリーズは、1つのデータ型しか持つことができません。
下記の様に、一次元の配列がシリーズです。
pandasの使い方
ではさっそくpandasの使い方をみていきましょう。
この記事ではハンズオンで学習する事を推奨していますので、是非皆さんの環境で実行してみてください。
サクッと試したい方は、google colaboratoryが簡単でおすすめです。
pandasのインストール
pandasを使うには、まずはインストールが必要です。
pipコマンドを使って、以下のようにインストールできます。
|
1 2 |
# インストール pip install pandas |
google colaboratoryの場合は特にインストールしなくても大丈夫です。
データの読み込みとデータフレームの作成
続いてデータを読み込んでデータフレームを作成してみましょう。
先ほども話したように、pandasではCSV、Excel、SQLなどの多くのデータ形式を扱うことができます。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd import seaborn as sns # irisファイルを読み込む df = sns.load_dataset('iris') # データを表示する print(df) |
まずお作法として、先頭行に「import pandas as pd」と書くようにしましょう。
こうする事でインポートしつつ、これ以降pandasを使う際はpdと書くだけで使える様になります。as以降でリネームしていますね。
ちなみにpdではなく、「as panda」など自分の好きな様に名前を付ける事もできますが、pdとするのが一般的です。
※今回はseabornにあるirisというデータセットを使っています。seabornに関しては別の記事で紹介します。
ちなみに各種ファイルから読みこむ際には、下記のように書きます。
|
1 2 3 4 5 6 7 8 |
# CSVファイルからデータを読み込む df = pd.read_csv('filename.csv') # Excelファイルからデータを読み込む df = pd.read_excel('filename.xlsx') # JSONファイルからデータを読み込む df = pd.read_json('filename.json') |
filename’の所に対象のファイルのパスを入れれば大丈夫です。
また「df =~」とする事で、読み込んだファイルをdfの中に入れる事ができ、データフレームを作成する事ができます。
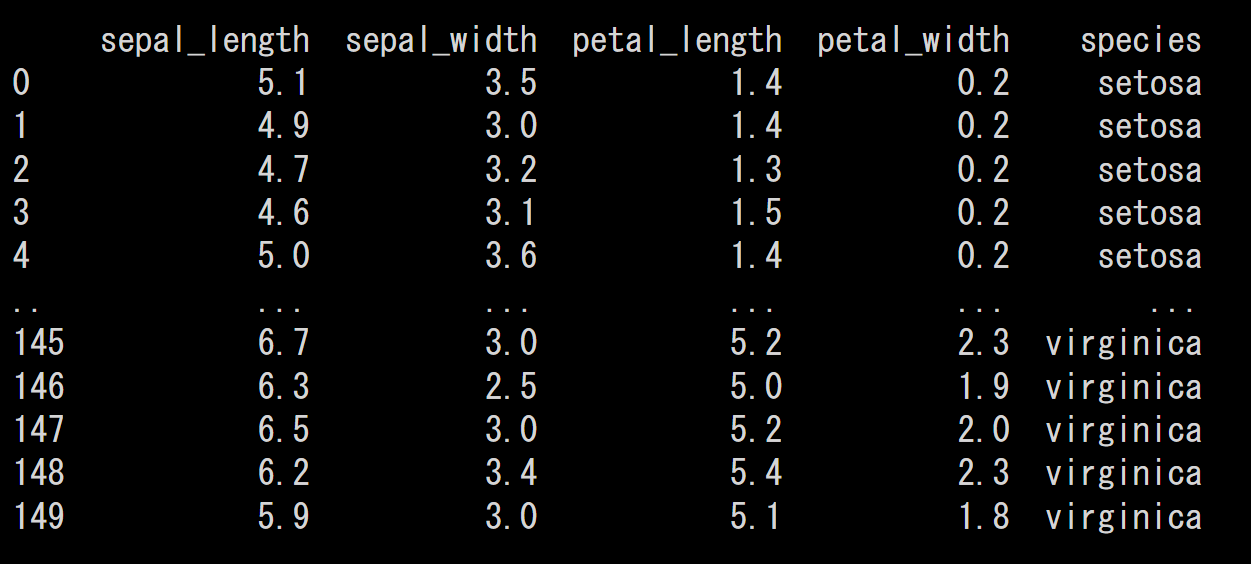
そして、print(df)と書く事で、↓のようにデータフレームの中を見る事ができます。
別の方法でデータフレームを作成する
データフレームの作成は、ファイルの読み込み以外にも以下の作成方法があります。
- ndarrayから作成
- dictionaryから作成
実務で使うシーンはファイル読み込みほどではありませんが、しっかりと押さえておきましょう。
ndarrayから作成
そもそもndarrayとは何かというと、
ndarrayとはNumPyパッケージで提供されるn次元配列(n-dimensional array)のことを指します。
ndarrayは、Pythonのリストやタプルとは異なり、同じデータ型の要素を格納することができ、多次元の場合でも高速な演算が可能です。
詳しくはNumPyの記事にて解説します。
まずは、numpyライブラリのインポートから始めましょう。
numpyはnpとするのが一般的です。
|
1 |
import numpy as np |
次にndarrayを作成します。ここでは、1~5の値が入るランダムな整数値を3×3の行列として作成しています。
|
1 2 3 |
# 1から5の値がランダムに入る、3×3の行列を作成 ndarray = np.random.randint(1,6, size=(3, 3)) ndarray |
array([[3, 1, 1],
[5, 5, 3],
[2, 2, 5]])
↑この様な行列が出来ると思います。
次はこのndarrayをデータフレームに変換しましょう。
pandasのDataFrameクラスを使用します。
|
1 2 3 4 |
# データフレームに変換 df = pd.DataFrame(ndarray) df |
こうする事で下記のデータフレームができます。

これだと行列名が分からないので使い辛いですね。そんな時は、行名(index)と列名(columns)をリストで渡してあげましょう。
|
1 2 3 4 5 6 |
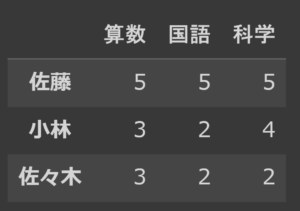
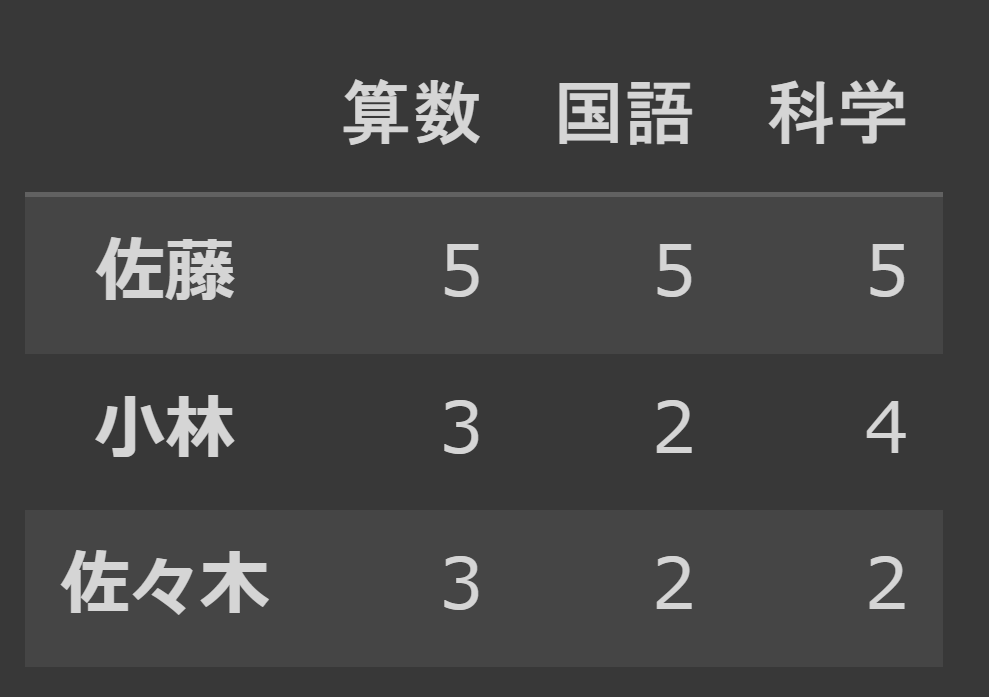
# 行列名を指定してからデータフレームの作成 columns = ['算数', '国語', '科学'] index = ['佐藤', '小林', '佐々木'] pd.DataFrame(data=ndarray, index=index, columns=columns) |
こうする事で、↓のような小学生の通知表を作成できます。
dictionaryから作成
では続いてdictionary(辞書)からの作成方法を見ていきましょう。
個人的にはndarrayよりもdictionaryから作成する方が多いです。
まず、dictionaryを用意します。dictionaryは、キーと値のペアでデータを格納するデータ構造です。
pandasのデータフレームをdictionaryから作成する場合、dictionaryのキーがデータフレームの列名に、値がデータフレームの列の値に対応します。
列が複数になる場合はlistで与えてあげましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
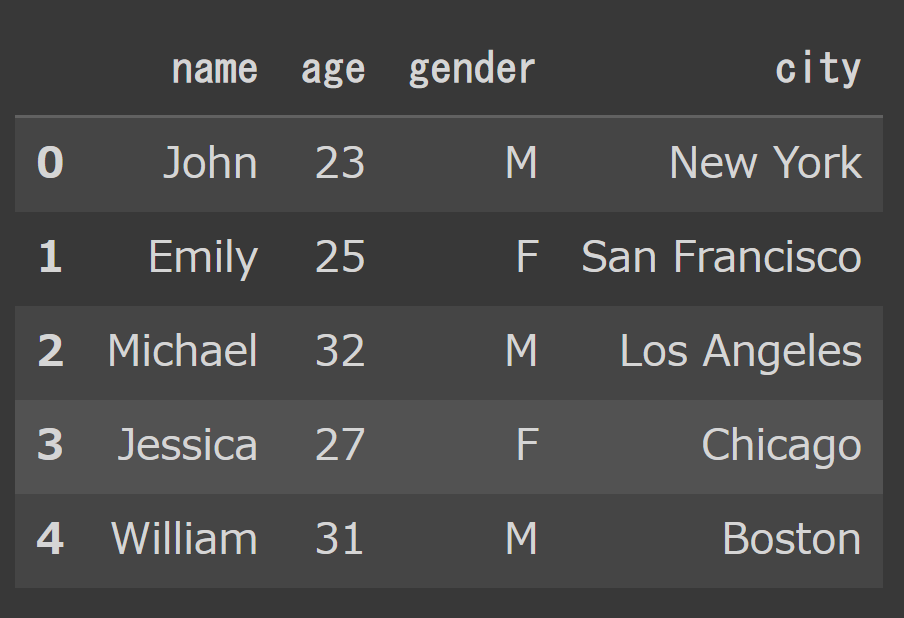
# dictionaryを用意する data = {'name': ['John', 'Emily', 'Michael', 'Jessica', 'William'], 'age': [23, 25, 32, 27, 31], 'gender': ['M', 'F', 'M', 'F', 'M'], 'city': ['New York', 'San Francisco', 'Los Angeles', 'Chicago', 'Boston']} # dictionaryからデータフレームを作成する df = pd.DataFrame(data) # データフレームを出力する df |
実行結果は以下のようになります。
まとめ
今回はpandasの基礎、データフレームの作成方法を紹介しました。
作成方法としては、以下の3種類がありましたね。
- ファイルから作成
- ndarrayから作成
- dictionaryから作成
データフレームの作成は必ず使いますので、必ず覚える様にしましょう~。
pythonの基礎を学びたい人は下記の記事をどうぞ。
「Pythonで始めるデータ分析:初心者のための完全ガイド」











