

今回はpandasチュートリアルの二回目になっています。
前回のがまだという方は↓の記事を参照ください。
【python】データ分析のための「pandas」チュートリアル①:データフレームの作成
今回は作成したデータフレームの中がどうなっているのか、実際に見ていきましょう!
全てサンプルコードを記載してあります。各々のpythonの環境で実際に手を動かしながら読み進めていってください。
サクッとやりたい方は、google colaboratoryが簡単でおすすめです。
データフレームの中身をhead()で確認しよう
まずは前回行った『iris』データをdfに入れる所から再開しましょう!
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd import seaborn as sns # irisファイルを読み込む df = sns.load_dataset('iris') # データを表示する print(df) |
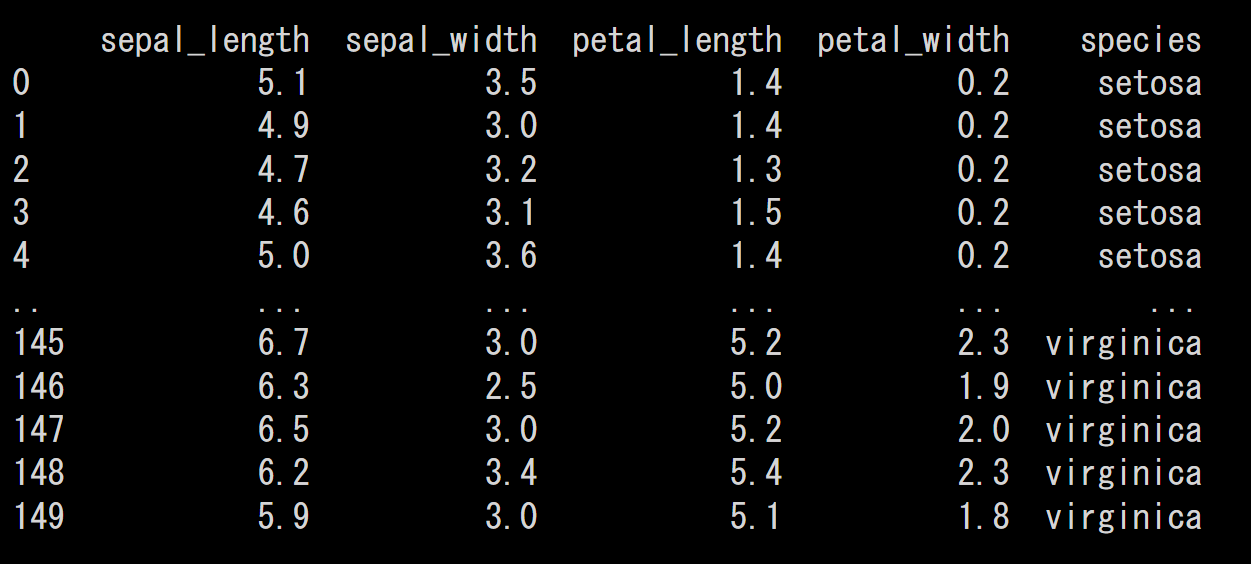
ここまでは大丈夫ですね?
画像のindexを見て欲しいのですが、0~4、145~149と途中のレコードが省略されて表示されています。
このまま見ても良いのですが、「先頭の10行までみたい!」といった時に、head()を使う事で任意の行まで表示する事ができます。
|
1 2 3 4 |
# デフォルト df.head() |
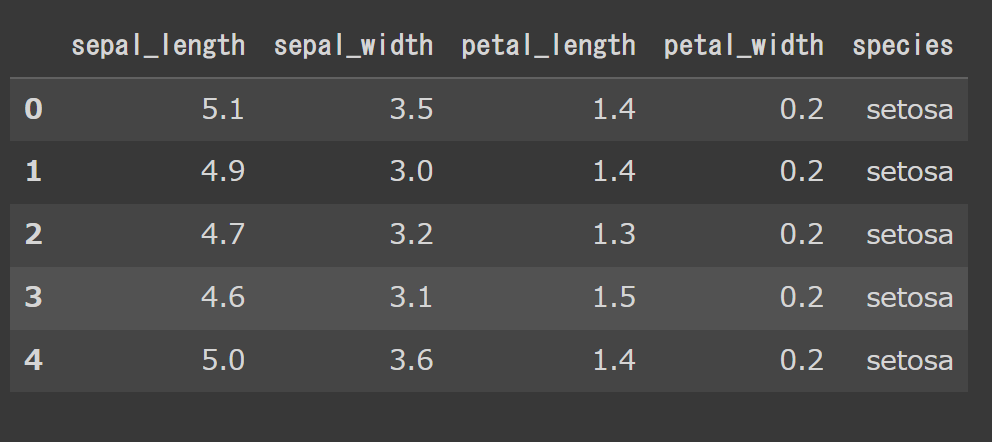
head()の()の中に何も入れないと5行だけ表示されます。(indexは0スタートです。)
この()の中に任意の数字を入れることで、好きな数のレコードを表示できます。
|
1 2 3 4 |
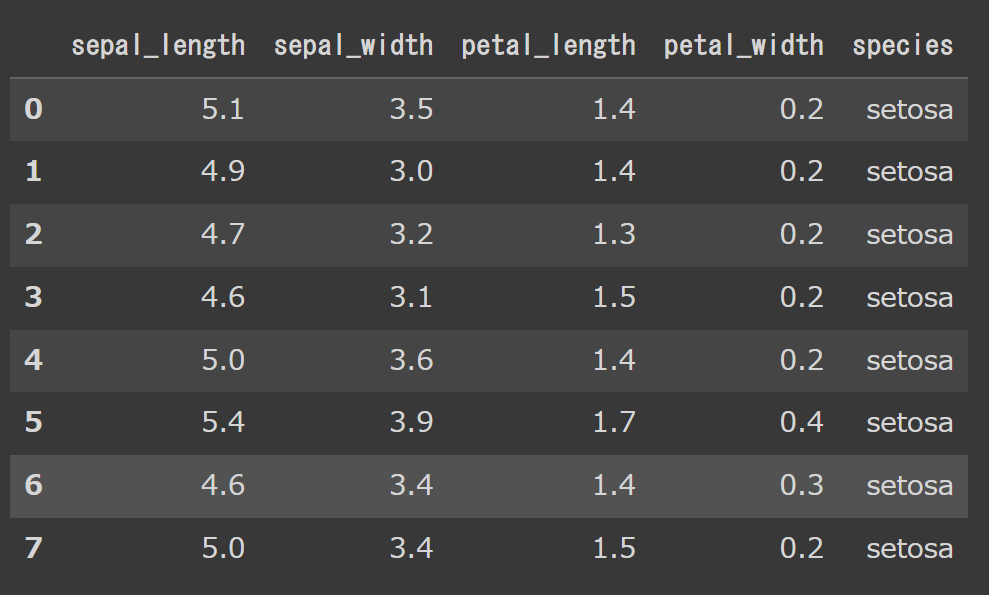
# 8行目まで表示 df.head(8) |
irisデータセットの説明
iris(アイリス)とは、植物の一種で、日本語では「アヤメ」と呼ばれています。irisデータセットは、このアイリスという植物の花の特徴量を計測したデータセットで、機械学習の分野でよく用いられる代表的なデータセットの一つです。
irisデータセットには、次の4つの特徴量が含まれています。
- sepal length(がく片の長さ):がく片(sepals)の長さをセンチメートル単位で表した値です。
- sepal width(がく片の幅):がく片(sepals)の幅をセンチメートル単位で表した値です。
- petal length(花びらの長さ):花びら(petals)の長さをセンチメートル単位で表した値です。
- petal width(花びらの幅):花びら(petals)の幅をセンチメートル単位で表した値です。
また、irisデータセットには、3種類のアヤメの種類が含まれており、それぞれ以下のようにラベル付けされています。
- Iris setosa
- Iris versicolor
- Iris virginica
describe()で統計情報を確認しよう
describe()はpandasデータフレームの統計情報を計算して表示するための便利なメソッドです。実務で非常に使えます。
サクッとデータの中身を確認したい時や、外れ値や欠損値があるかなどを把握することができます。
|
1 2 3 4 |
# 統計量の確認 df.describe() |
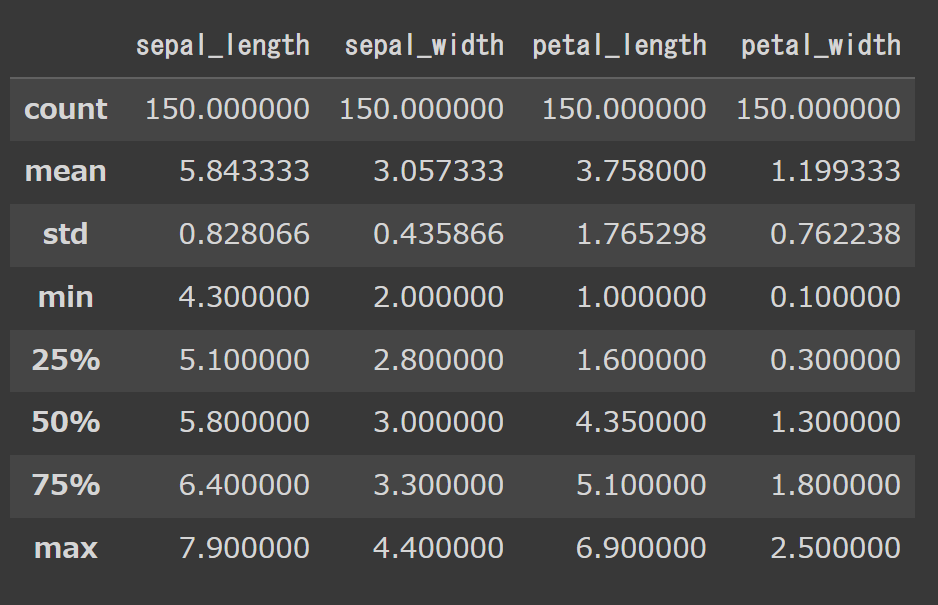
見方として、列(column)の部分はdfに入っている数値型のカラムだけ自動で抽出してくれます。
行の部分に関しては、↓のようになっています。
- count: データの個数を表します。
- mean: データの平均値を表します。
- std: データの標準偏差を表します。
- min: データの最小値を表します。
- 25%: データの下位25%の値を表します。
- 50%: データの中央値を表します。
- 75%: データの上位25%の値を表します。
- max: データの最大値を表します。
corr()で相関係数を確認しよう
これもデータサイエンスでは非常に良く使います。
df.corr()とする事で、数値型の列同士の相関係数を全てパッと出してくれるのです。
相関係数とは
簡単に説明すると、相関係数は2つの変数間の関係の強さを数値で表す統計指標の一つです。具体的には、2つの変数がどの程度同時に変化するかを表現します。
相関係数は、-1から1までの値を取り、絶対値が1に近いほど2つの変数は強い相関があるといえます。
逆に-1に近いほど、負の相関があるといえます。
では実際に出してみましょう!
|
1 2 3 4 |
# 相関係数 df.corr() |
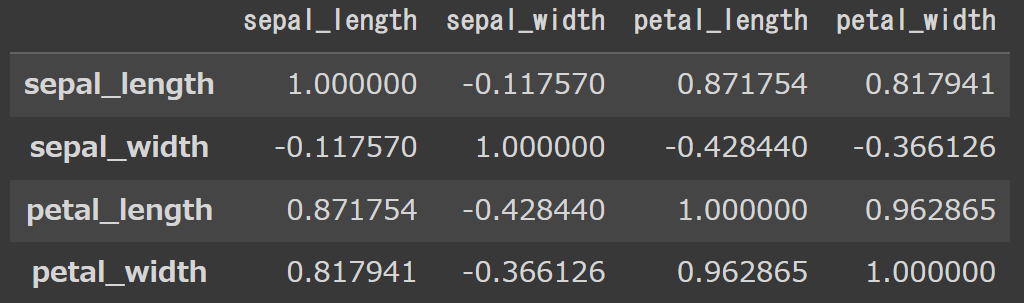
注意点として、対角線上は同じカラム同士の相関なので、1になっています。
petal_widthとpetal_lengthの相関は0.96…と非常に高い事が分かりますね。
まあ、花びらの長さが長くなると花びらの幅も長くなるのは当たり前ですよね、、
逆にsepal_width(がく片の幅)とpetal_length(花びらの幅)は負の相関がある事が分かります。
カラム名(列名)を抽出する
なにかと見たくなるのが、dfに入っているカラム名ですね!
これも簡単に見る事ができます。
|
1 2 3 4 |
# カラム名だけを取得 df.columns |
Index([‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], dtype=’object’)
リストで表示されていますね!
[]で列を指定する
全部の列を毎回抽出せずに、指定の列だけを見たい!そんな時はブラケット→[]を使いましょう。
列を[]で抽出するには、データフレームの列名を[]で囲って指定します。
df[‘カラム名’]←こんな感じです。
|
1 2 3 4 |
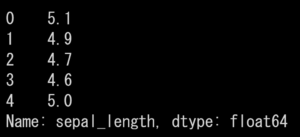
# sepal_lengthカラムだけを抽出 df['sepal_length'] |
これと先ほどやったhead()を組み合わせて、指定のカラムの指定行まで抽出する事も出来ます。
|
1 2 3 4 |
# sepal_lengthカラムの5行目までを抽出 df['sepal_length'].head() |
複数カラムの指定方法
指定するカラムも、もちろん複数指定ができます。
[]のなかにさらに[]を入れてリストで渡してあげましょう。
|
1 2 3 |
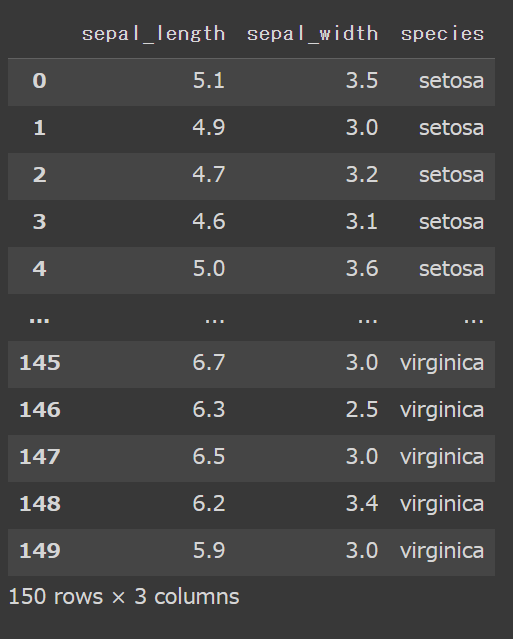
# 複数カラムを指定 df[['sepal_length', 'sepal_width', 'species']] |
行を指定して抽出する
では続いて行を指定して抽出する方法をみていきましょう。
いくつか方法があります。
ilocを使う
iloc()を使う事で、簡単に指定できます。
行と列のインデックスを数値で指定してデータを抽出するメソッドです。iloc[行,列]という形式で指定します。
|
1 2 3 |
# ilocを使って1行、3列目の値を抽出 df.iloc[0,2] |
->1.4
また、任意の行を範囲指定する事もできます。
iloc[行:列]とします。
|
1 2 |
# ilocを使って2行目から5行目を取得 df.iloc[1:5] |
ちなみに、df.iloc[1:5, 1:3]とするとカラムの指定も合わせて出来ます。
|
1 2 |
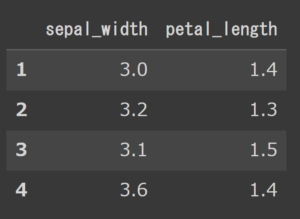
# カラムも一緒に指定 df.iloc[1:5,1:3] |
locを使う
locは行と列のラベルを指定してデータを抽出するメソッドです。loc[行ラベル,列ラベル]という形式で指定します。
|
1 2 |
# locで取得 df.loc[1:5,['sepal_length','sepal_width']] |
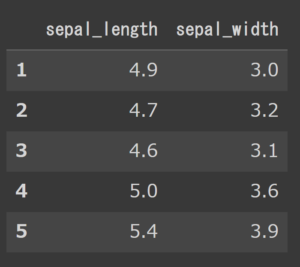
drop()で削除しよう
最後にdrop()の使い方をマスターしましょう!
drop()はデータフレームから行または列を削除するために使用される関数です。この関数を使うことで、データの前処理や欠損値の扱いに役立ちます。
今後、機械学習などデータ分析をやるとなったら絶対に使いますので、挙動を覚えておきましょう。
|
1 2 |
# dropの使い方 df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise') |
()の中の引数に色々指定する事で、挙動を変更する事ができます。
labels: 削除する行または列のインデックスまたは名前を指定します。axis: 削除する方向を指定します。0は行を、1は列を表します。indexまたはcolumns: 削除する行または列のラベルを指定します。level: 削除する行または列が階層的インデックスの場合、削除する階層を指定します。inplace:Trueを指定すると、データフレームの内容を変更し、新しいオブジェクトを返さなくなります。errors: 存在しないラベルを指定した場合にエラーを発生させるかどうかを指定します。
う~ん、一度に覚えるのは難しいですね、、
まずは指定の行を落とすやり方を覚えておけばオッケーです。
|
1 2 |
# カラムを指定して削除 df.drop('sepal_length', axis=1) |
このように、削除対象のカラムを指定してaxis引数に1を入れる事で対象の列を削除する事ができます。
sepal_lengthのカラムが無くなってますね~!
ちなみに↓の様にしても同じ結果となります。
|
1 2 |
# カラムを指定して削除 df.drop(columns='sepal_length') |
無事に削除が出来たと思います。
しかし、注意して欲しい点として、上記のやり方ですと元のdfではカラム削除がされておらず、これ以降にdf~としても対象のカラムは削除されていないのです。
dfからカラム削除を行う
実際にデータフレームから削除を行う方法は2種類ありますので紹介します。
まずはinplace引数にTrueを指定する事で削除する事ができます。
|
1 |
df.drop('sepal_length', axis=1, inplace=True) |
これでデータフレーム自体からカラム削除が出来ました。
また、2つ目の方法は下記のやり方です。
|
1 2 |
# データフレームからカラムを削除 df = df.drop('sepal_length', axis=1) |
このように、dfからdropした後にまたdfに入れる事で削除されたデータフレームが出来上がります。
ここで疑問に思うのが、同じdfに入れるのではなく、「df_drop」にするなどして新しいdfを作った方が良さそうな気もしますよね?
しかし、これはメモリの観点からおススメ出来ません。
今回のように、数百行のレコードだったら問題ないのですが、実務では何万・何十万ものレコード数になったり、カラム数も100以上になったりします。
そうなると、ポンポンとdfを作ってしまうとすぐにメモリ不足になってしまいますので注意しましょう。
まとめ
いかがでしたでしょうか?
今回は作成したデータフレームの中身を見て行く作業を行いました。
- df.head()
- df.describe()
- df.corr()
特に初めてのデータセットに触れる場合は、上記の3点セットを行い、ばくっとデータの傾向を掴む事が多いです。
是非、今回やった内容を忘れないように復習しましょう!











